Didattica → Sistemi e Reti → L'Unità di decodifica
Come abbiamo detto un microprocessore è in grado di eseguire un certo insieme di istruzioni di tipo logico-aritmetiche.
Il microprocessore esegue istruzioni come sequenze di bit che costituiscono il linguaggio macchina e che esiste un linguaggio mnemonico chiamato assembly che permette di programmare in maniera relativamente più semplice programmi con molte istruzioni.
Non ci resta che capire come sia possibile la conversione di macroprogrammi da linguaggio assembly a linguaggio macchina.
Questo è possibile tramite una struttura contenente un set di istruzioni. Una corrispondenza cioè tra codici mnemonici che individuano una operazione e la sequenza in bit associata.
Considerando un microprocessore con parallelismo ad 8 bit e indirizzamento a 16 bit, potremmo avere la seguente tabella con il set di istruzioni.
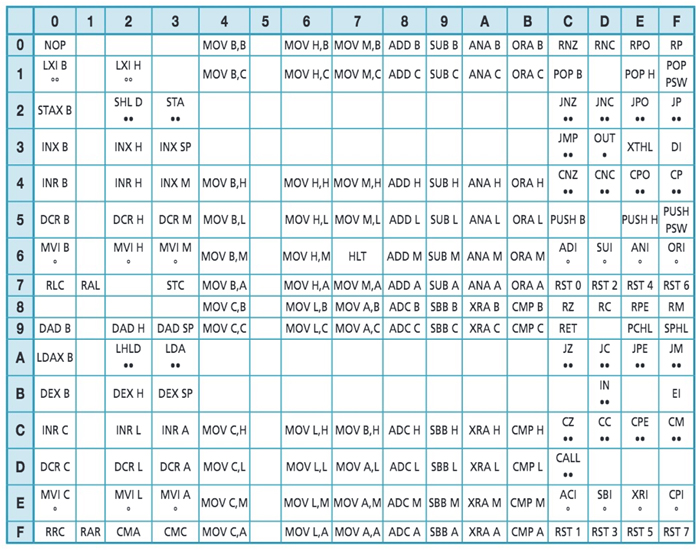
Fig. 1 - Esempio di tabella di istruzioni
Ogni istruzione è identificata dall’intersezione di riga e colonna (nella tabella espresse come valori esadecimali). L’equivalente espresso in binario come composizione colonna-riga, indica al microprocessore l’operazione da effettuare.
Ad esempio il codice operativo ADD B (che vuol dire “somma il contenuto del registro B con l’accumulatore ACC e salvalo dentro ACC”) è individuato dal valore 80h in base esadecimale (dall’intersezione colonna (8) riga (0)), in forma binaria è pari a:
816 = 10002
016 = 00002
8016 = 1000 00002
L’istruzione ADD B quindi sarà 1000 00002.
Questo codice va suddiviso però tra i primi cinque bit più significativi e i tre bit meno significativi che hanno significati diversi.
I primi cinque bit rappresentano il codice del commando (in questo caso ADD) mentre i restanti tre bit indicano l’indirizzo del registro B.
Questo vuol dire che modificando gli ultimi tre bit possiamo cambiare il registro su cui operare.
Es. ADD C avrà come sequenza: 10000 0012.
Si può quindi generalizzare il codice operativo della somma come ADD r dove al posto di r possiamo mettere la sequenza binaria che individual il registro su cui opeare.
Registro B = 0002
Registro C = 0012
Registro H = 1002
Registro L = 1012
Registro M = 1102
Registro A = 1112
Infatti:
ADD B (8016) → 10000 0002
ADD C (8116) → 10000 0012
ADD H (8416) → 10000 1002
ADD L (8516) → 10000 1012
ADD M (8616) → 10000 1102
ADD A (8716) → 10000 1112
Il set di istruzioni è suddiviso nei seguenti gruppi:
Nella tabella del set di istruzioni, sono specificati dei cerchietti, a volte uno a volte due. Quando si ha un solo cerchietto si indica che il dato spostato ha dimensione 8 bit. Quando invece i cerchietti sono due invece il dato è a 16 bit.
I cerchietti neri sono associati alle operazioni che producono spostamento di dati, quelli bianchi invece sono associati alle operazioni che producono spostamenti di indirizzi (Fig. 1).
Questa è una istruzione di un solo byte e in base alla disposizione all’interno della tabella, il formato del codice operativo è il seguente: 01000SSS2. Infatti la Colonna rimane invariata (ad esempio MOV H, A o MOV H, C etc.) e cambia solo la riga.
Altre operazioni MOV invece variano le colonne e restano invariate le righe in base ad un formato del codice operative del tipo 01DDD0012 ad esempio.
Più in generale le operazioni MOV r, d sono caratterizzati dai primi due bit in commune 01 e prevedono un formato del tipo 01DDDSSS dove al posto di DDD si indica la sequenza di bit del registro in cui viene spostato il dato e al posto di SSS la sequenza di bit da cui viene spostato il dato.
Tuttavia se volessimo spostare in un dato registro un dato che non è prelevato da un altro registro ma è un dato vero e proprio, avremo bisogno oltre al byte dell’operazione, anche il byte del dato. In tal caso avremo due istruzioni. La prima istruzione conterrà l’operazione di memorizzazione vera e propria e la seconda istruzione conterrà esclusivamente il dato.
Se vogliamo l’operazione assumerà il seguente significato: copia nel registro il dato composto dai seccessivi 8 bit.
Facciamo un esempio: MVI H, EA. Questo commndo richiede di spostare il dato espresso in formato esadecimale EA (di 8 bit) nel registro H.
La I sta per Immediato.
Dobbiamo quindi spezzare in due parti l’operazione. La prima parte MVI H che avrà come codice dell’operazione 26, in binario 001001102 che costituirà la prima microistruzione. La seconda parte è invece il dato che deve essere memorizzato in H cioè EA, in binario 111010102 (i successivi 8 bit). Ovviamente questa operazione prevede tutte le varianti:
MVI B, dato a 8bit
MVI C, dato a 8bit
MVI L, dato a 8bit
MVI A, dato a 8bit
MVI M, dato a 8bit
La forma generale sarà quindi MVI r, dato a 8bit.
Primo byte: 00DDD1102 (dove al posto di DDD indichiamo il registro di destinazione r o se vogliamo la colonna del set di istruzioni) Secondo byte: dato a 8bit
Facciamo l’esempio del commando LXI SP, FFFE (dato a 16bit).
Con questo commando si vuole spostare gli 8 bit meno significativi del dato nel registro SPl (cioè la parte meno significativa del registro SP) e gli 8bit più significativi del registro SPh (cioè la parte più significativa del registro SP).
Se la tecnica di memorizzazione segue il format little-endian, allora dobbiamo spezzare l’operazione in tre parti (questo ovviamente sempre perchè il parallelismo del microprocessore è a 8 bit).
Primo byte: LXI SP con codice operazione 31, in binario 001100012
Secondo byte: FE in binario è 111111102 (byte meno significativo dei 16 bit)
Terzo byte: FF in binario 1111111112 (byte più significativo dei 16 bit)
Quinidi il secondo byte (111111102) verrà salvato in SPl, mentre il terzo byte (111111112) verà salvato in SPh.
Ovviamente anche in questo caso esistono le variant: LXI B, dato a 16bit, LXI H dato a 16bit, etc.
Si noti che le precedenti forme sono delle abbreviazioni. Ad esempio LXI B sottointende che si tratti di LXI BC, LXI H sottointende che si tratti di LXI HL, e via dicendo.
Tra le istruzioni di movimento dati ne esistono altre 6.
Sono entrambe operazioni ad un byte.
ADD prende il contenuto di un registro lo somma con il contenuto del registro ACC e il risultato viene posto nello stesso registro ACC.
ADC, invece, somma il contenuto di un registro con ACC e con il flag C del registro di stato (quello del riporto). Il risultato viene posto nell’accumulatore.
Oltre ad ADD e ADC, esistono anche le operazioni ADI e ACI (a due byte).
L’operazione ADI somma al contenuto dell’accumulatore al contenuto della locazione di memoria puntata dal secondo byte.
L’operazione ACI somma il contenuto dell’accumulatore al contenuto della locazione di memoria puntata dal secondo byte e al flag C del registro di stato.
Ad esempio DAD B effettua la somma tra il contenuto di HL ed il contenuto di BC ed il risultato lo memorizzano in HL.
Sono entrambe ad un byte.
L’operazione SUB effettua una sottrazione del contenuto dell’accumulatore ACC e il contenuto di uno dei registri B, C, H, L, o della locazione di memoria M. Il risultato viene inserito nell’ACC.
L’operazione SBB, invece, effettua una sottrazione del contenuto dell’accumulatore, il contenuto di uno dei registri e il flag C del registro di stato.
Oltre a SUB e SBB, esistono anche SUI e SBI (a due byte).
SUI permette di sottrarre al contenuto dell’accumulatore il contenuto della locazione di memoria indirizzata dal secondo byte. Il risultato viene salvato nell’accumulatore.
SBI, invece, permette di sottrarre al contenuto dell’accumulatore il contenuto della locazione di memoria indirizzata dal secondo byte e il flag C del registro di stato. Il risultato viene salvato nell’accumulatore.
DCR r, decrementa di 1 il registro r.
Esistono anche istruzioni di incremento e decremento a due byte: INX e DEX.
INX permette di incrementare di 1 le coppie di registri. Ad esempio INX B, incrementa di 1 i registri BC, INX H, incrementa di 1 i registri HL, etc.
Allo stesso modo DEX decrementa di 1 le coppie di registri. Ad esempio DEX B, decrement di 1 I registri BC, etc).
Effettuano una sottrazione tra il contenuto dell’ACC e il contenuto di un registro (B, C, H, L) o della locazione M. Se il contenuto di ACC è minore del contenuto del registro allora il flag C sarà settato ad 1. Zero altrimenti.
L’operazione è la CMP.
Una seconda operazione di confronto è quella immediate CPI che è a due byte.
Essa effettua la sottrazione tra il contenuto di ACC e il secondo byte.
E’ possibile effettuare anche l’operazione prodotto logico ANI a due byte che effetua l’AND tra il contenuto dell’ACC e il secondo byte.
Una seconda operazione è ORI (a due byte) che permette di applica l’OR tra il contenuto dell’ACC con il secondo byte.
La corrispondente operazione a due byte è XRI che applica lo XOR tra l’accumulatore e il secondo byte.
RAR, invece, fa lo shift a destra del bit dell’accumulatore liberando il posto del bit più significativo sostituendolo con il bit del registro di stato C (carry). Il bit rimosso poi viene memorizzato in C.
Le istruzioni RLC e RRC sono identiche alle precedenti. L’unica differenza è che non viene inserito il bit del registro di stato C (carry).
In RLC, lo spazio vuoto viene sostituito con il bit più significativo. Mentre in RRC, lo spazio vuoto viene sostituito con il bit meno significativo.
Il bit rimosso, anche in queste operazioni, viene memorizzato nel registro di stato C.
Piuttosto che eseguire l’istruzione successive, si esegue l’istruzione all’indirizzo specificato dal secondo e terzo byte. L’istruzione “JMP, indirizzo a 16 bit” è una istruzione di salto incondizionato. Viene sposato nel PC l’indirizzo dei 16bit (primo e secondo byte) e la prosecuzione del programma riprende dalla locazione di memoria indirizzata dai 16bit.
Chiaramente quando viene effettuato un JMP, il vecchio contenuto del PC viene perse per cui per ritornare all’istruzione precedente è necessario in nuovo JMP.
A differenza di JMP, gli altri salti possibili sono JNZ, JNC, JPO, JP, JZ, JC, JPE e JM che sono salti condizionati perchè il salto è condizionato dal risultato dell’operazione aritmetica o logica. Se tale condizione è verifica, il salto è esattamente quello di JMP altrimenti l’esecuzione procede all’istruzione successiva.
Il comportamento dei salti condizionati è legato al contenuto del registro di stato.
Quando il microprocessore esegue una istruzione di chiamata ad un sottoprogramma, deve salvare il contenuto attuale del PC nella parte di RAM chiamata Stack che è indirizzata dallo Stack Pointer (che si decrementa/incrementa in base a se riceve dei dati e se li rimuove).
Quando l’esecuzione del sottoprogramma termina, il microprocessore recupera il vecchio contenuto del PC dallo stack, lo ripristina nel PC e ritorna ad eseguire il programma chiamante.
La chiamata ad un sottoprogramma avviene tramite l’istruzione incondizionata CALL, indirizzo a 16bit (a tre byte). Questa operazione come anticipato salva nello Stack il contenuto del Program Counter, e recupera l’istruzione dalla memoria all’indirizzo composto dalla combinazione del primo e del secondo byte.
Quando viene eseguita la CALL, il byte più significativo del PC viene salvato nel byte più significativo della locazione puntata da SP (SPH) mentre il byte meno significativo di PC viene salvato nel byte meno significativo della locazione puntata da SP (SPL). A questo punto il contenuto di SP viene decrementato di 1.
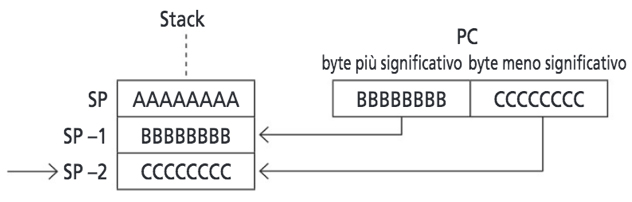
Fig. 3 - Schema di funzionamento della chiamata a sottoprogramma
Una volta terminata l’esecuzione del sottoprogramma, l’operazione di ritorno che permette di ritornare al programma principale è la RET.
Questa operazione recupera il contenuto del PC salvato nello stack (raggiungibile tramite il registro SP) prima il byte meno significativo, poi il byte più significativo (in base a se è di tipo little-endian o big-endian). Dopodichè viene decrementato lo stesso SP.
Con questo meccanismo viene ripristinato il PC originario e anche SP punterà alla cella di partenza dello Stack.
Chiaramente è possibile anche continuare ad invocare più volte sottoprogrammi annidati fra loro e il meccanismo continuerebbe a funzionare sfruttando tutta la profondità dello Stack.
Esistono anche istruzioni a chiamata condizionata (a tre byte): CNZ, CNC, CPO, CP, CZ, CC, CPE, CM a cui corrispondono le chiamate di ritorno RNZ, RNC, RPO, RP, RZ, RC, RPE, RM.
Sono divise in quattro gruppi:
Il secondo byte rappresenta la periferica che si vuole abilitare alla lettura del contenuto del bus dei dati. Essendo 8bit possiamo indirizzare ben 256 periferiche diverse.
Nel caso di IN si sta cercando di abilitare la periferica a scrivere sul bus dei dati mentre nel caso di OUT si sta cercando di abiltarla a leggere sul bus dei dati.
L’abilitazione avviene tramite l’invio di opportuni segnali da parte dell’unità di controllo e termporizzazione verso il sistema esterno.
Questo meccanismo può essere anticipato da uno scambio di segnali che fanno da preludio alla comunicazioni tra microprocessore e sistema esterno.
Quando una periferica vuole comunicare con il microprocessore invia una richiesta di interrupt settando INT a 0.
Le operazioni di abilitazione delle richieste di interruzioni sono EI (che abilita la richiesta) o DI (che disabilita la richiesta) entrambi ad un byte.
Ad esempio le operazioni SPHL o XHLT (entrambe a due byte) consentono lo scambio tra registri. SPHL consente di copiare il contenuto della SP in HL mentre XHLT consente di scambiare i contenuti di SP e LT.
Tra queste istruzioni compaiono anche PUSH e POP che consentono di spostare dati all’interno dello stack ed estrapolarli.
Ogni volta che viene invocate una PUSH il contenuto di BC o HL viene spostato nello stack e lo SP viene decrementato. Mentre quando viene effettuata una POP viene recuperate il contenuto puntato da SP e spostato in BC o in HL e poi PC viene incrementato.
Vediamo ora degli esempi di cicli di istruzione completi.
Ciclo istruzione MOV r1 , r2
L’istruzione MOV esegue lo spostamento del contenuto del registro r2 all’interno del registro r1 .
Vediamo quali sono gli stati macchina.
Ciclo di fetch: Viene immesso sul bus degli indirizzi esterno l’indirizzo della memoria presente nel PC (T1), dopodiché viene prelevata dalla memoria RAM l’istruzione a cui punta tale indirizzo e viene salvata nell’Instruction Register (T2). A questo punto l’istruzione viene presa dall’Instruction Register e viene passata all’unità di decodifica e contemporaneamente il PC viene incrementato (T3).
Ciclo di Execute: Il microprocessore è ora pronto per l’esecuzione dell’istruzione in quanto dovrà semplicemente accedere ai due registri interni e utilizzare il registro di appoggio TEMP. Quindi il ciclo di execute prevederà: la memorizzazione del contenuto del registro r2 all’interno di TEMP (T4) e in fine la memorizzazione del contenuto di TEMP nel registro r1 .
Si noti che l’istruzione precedente prevede un solo ciclo macchina in quanto il microprocessore recupererà un valore dalla memoria esterna soltanto una volta.
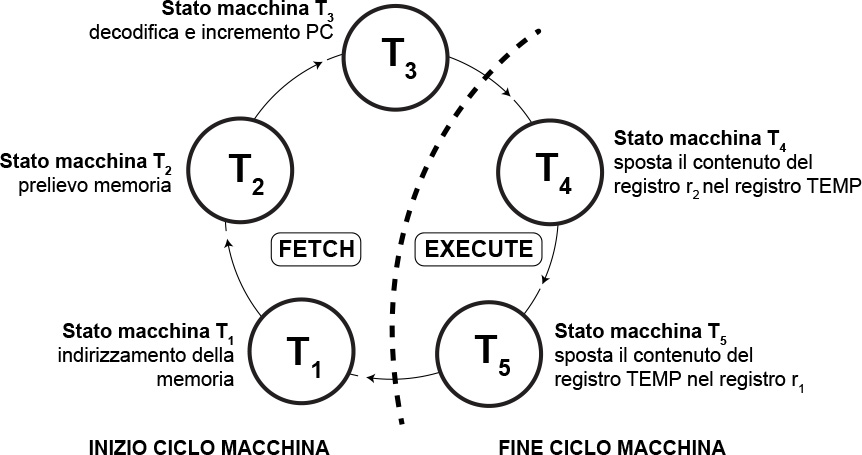
Fig. 4 - Flusso di esecuzione dell'istruzione MOV r1 , r2
Ciclo istruzione MOV r, M
Tale comando prevede lo spostamento del contenuto della memoria M puntato dal contenuto di HL, nel registro interno r.
Le singole microistruzioni saranno le seguenti:
Ciclo di Fetch. Viene immesso sul bus degli indirizzi esterno l’indirizzo della cella di memoria a cui punta PC (T1), dopodiché viene prelevata l’istruzione contenuta a quell’indirizzo e spostata nel registro interno Instruction Register (T2). L’istruzione viene spostata dall’Instruction Register all’unità di decodifica e il PC viene incrementato (T3).
Ciclo di Execute. Il microprocessore esegue l’istruzione tramite l’unità di controllo e di temporizzazione. Tuttavia c’è da recupeare l’indirizzo della cella di memoria contenente il dato da spostare nel registro interno r. Dunque viene immesso sul bus degli indirizzi esterno, l’indirizzo contenuto nella coppia di registri HL che punta alla cella della memoria M (T1*). Dopodichè viene recuperato il contenuto di M e spostato nel registro r (T2*).
Si noti come in questo caso abbiamo due cicli macchina in quanto per due volte si accede alla memoria esterna. La prima volta per recuperare l’istruzione da eseguire. La seconda volta per recuperare il dato nella locazione di memoria M.
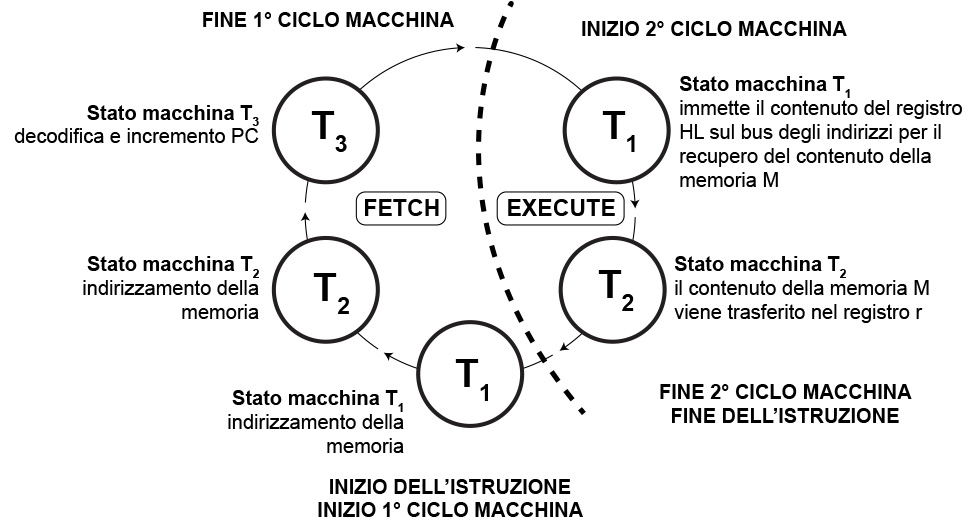
Fig. 5 - Flusso di esecuzione dell'istruzione MOV r, M
Ciclo di istruzione MVI M, dato a 8 bit
Tale comando prevede un movimento dati immediato. Il dato di 8 bit viene memorizzato nella cella di memoria M (puntata cioè dalla coppia di indirizzi HL).
Questa istruzione, a differenza delle precedenti, è a due byte.
Ciclo di Fetch.: viene immesso l’indirizzo contenuto nel PC sul bus degli indirizzi (T1), viene prelevata l’istruzione dalla memoria RAM e memorizzata nell’Instruction Register (T2), l’istruzione dall’Instruction Register passa all’unità di decodifica e il PC viene incrementato (T3).
Ciclo di Execute: essendo questo comando a due byte, è necessario recuperare il secondo byte. Viene immesso sul bus degli indirizzi esterno l’indirizzo contenuto del PC precedentemente incrementato in modo da recuperare il contenuto della cella di memoria successiva (T1*), viene incrementato nuovamente il PC (T2*), il contenuto recuperato dalla memoria viene spostato in TEMP (T3*). A questo punto bisogna effettuare una nuova chiamata alla memoria per individuare la cella della memoria esterna dove andare a salvare il dato. Si immette quindi sul bus degli indirizzi esterno l’indirizzo contenuto nella coppia di registri interna HL (T1**). Dopodiché si immette il contenuto di TEMP sul bus dei dati esterno per salvare il dato nella memoria RAM (2**).
In questo caso gli stati macchina sono otto mentre i cicli macchina sono ben tre essendo che per tre volte indirizziamo la memoria RAM.
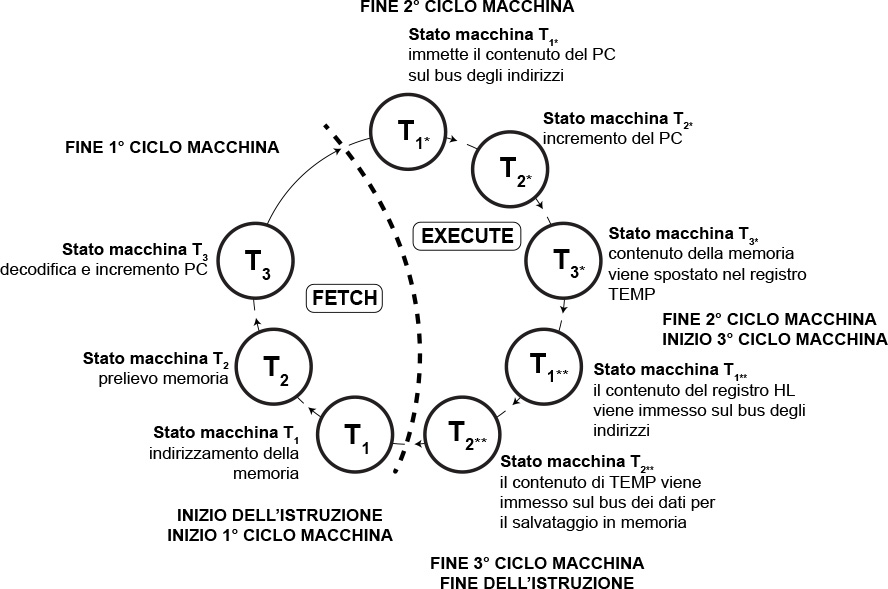
Fig. 6 - Flusso di esecuzione dell'istruzione MVI M, dato a 8 bit
L'Unità di decodifica
Come abbiamo detto un microprocessore è in grado di eseguire un certo insieme di istruzioni di tipo logico-aritmetiche.
Il microprocessore esegue istruzioni come sequenze di bit che costituiscono il linguaggio macchina e che esiste un linguaggio mnemonico chiamato assembly che permette di programmare in maniera relativamente più semplice programmi con molte istruzioni.
Non ci resta che capire come sia possibile la conversione di macroprogrammi da linguaggio assembly a linguaggio macchina.
Questo è possibile tramite una struttura contenente un set di istruzioni. Una corrispondenza cioè tra codici mnemonici che individuano una operazione e la sequenza in bit associata.
Considerando un microprocessore con parallelismo ad 8 bit e indirizzamento a 16 bit, potremmo avere la seguente tabella con il set di istruzioni.
Fig. 1 - Esempio di tabella di istruzioni
Ogni istruzione è identificata dall’intersezione di riga e colonna (nella tabella espresse come valori esadecimali). L’equivalente espresso in binario come composizione colonna-riga, indica al microprocessore l’operazione da effettuare.
Ad esempio il codice operativo ADD B (che vuol dire “somma il contenuto del registro B con l’accumulatore ACC e salvalo dentro ACC”) è individuato dal valore 80h in base esadecimale (dall’intersezione colonna (8) riga (0)), in forma binaria è pari a:
816 = 10002
016 = 00002
8016 = 1000 00002
L’istruzione ADD B quindi sarà 1000 00002.
Questo codice va suddiviso però tra i primi cinque bit più significativi e i tre bit meno significativi che hanno significati diversi.
I primi cinque bit rappresentano il codice del commando (in questo caso ADD) mentre i restanti tre bit indicano l’indirizzo del registro B.
Questo vuol dire che modificando gli ultimi tre bit possiamo cambiare il registro su cui operare.
Es. ADD C avrà come sequenza: 10000 0012.
Si può quindi generalizzare il codice operativo della somma come ADD r dove al posto di r possiamo mettere la sequenza binaria che individual il registro su cui opeare.
Registro B = 0002
Registro C = 0012
Registro H = 1002
Registro L = 1012
Registro M = 1102
Registro A = 1112
Infatti:
ADD B (8016) → 10000 0002
ADD C (8116) → 10000 0012
ADD H (8416) → 10000 1002
ADD L (8516) → 10000 1012
ADD M (8616) → 10000 1102
ADD A (8716) → 10000 1112
Il set di istruzioni è suddiviso nei seguenti gruppi:
- istruzioni di movimento dati;
- istruzioni aritmetiche e logiche;
- istruzioni di salto;
- istruzioni di manipolazione dello stack, dell’I/O, di controllo macchina e di gestione di interruzioni;
Istruzioni di movimento
Sono le istruzioni che permettono di spostare i dati tra i registri di utilità oppure dai registri di utilità alla memoria e viceversa.Nella tabella del set di istruzioni, sono specificati dei cerchietti, a volte uno a volte due. Quando si ha un solo cerchietto si indica che il dato spostato ha dimensione 8 bit. Quando invece i cerchietti sono due invece il dato è a 16 bit.
I cerchietti neri sono associati alle operazioni che producono spostamento di dati, quelli bianchi invece sono associati alle operazioni che producono spostamenti di indirizzi (Fig. 1).
Istruzioni di movimento ad un byte.
Ad esempio le operazioni MOV sono le operazioni che spostano il contenuto del registro d nel registro r.Questa è una istruzione di un solo byte e in base alla disposizione all’interno della tabella, il formato del codice operativo è il seguente: 01000SSS2. Infatti la Colonna rimane invariata (ad esempio MOV H, A o MOV H, C etc.) e cambia solo la riga.
Altre operazioni MOV invece variano le colonne e restano invariate le righe in base ad un formato del codice operative del tipo 01DDD0012 ad esempio.
Più in generale le operazioni MOV r, d sono caratterizzati dai primi due bit in commune 01 e prevedono un formato del tipo 01DDDSSS dove al posto di DDD si indica la sequenza di bit del registro in cui viene spostato il dato e al posto di SSS la sequenza di bit da cui viene spostato il dato.
Istruzioni di movimento ad indirizzamento immediato a due byte
Nel caso del movimento di dati da un registro ad un altro l’istruzione di movimento è una sola ed è basata su un solo byte.Tuttavia se volessimo spostare in un dato registro un dato che non è prelevato da un altro registro ma è un dato vero e proprio, avremo bisogno oltre al byte dell’operazione, anche il byte del dato. In tal caso avremo due istruzioni. La prima istruzione conterrà l’operazione di memorizzazione vera e propria e la seconda istruzione conterrà esclusivamente il dato.
Se vogliamo l’operazione assumerà il seguente significato: copia nel registro il dato composto dai seccessivi 8 bit.
Facciamo un esempio: MVI H, EA. Questo commndo richiede di spostare il dato espresso in formato esadecimale EA (di 8 bit) nel registro H.
La I sta per Immediato.
Dobbiamo quindi spezzare in due parti l’operazione. La prima parte MVI H che avrà come codice dell’operazione 26, in binario 001001102 che costituirà la prima microistruzione. La seconda parte è invece il dato che deve essere memorizzato in H cioè EA, in binario 111010102 (i successivi 8 bit). Ovviamente questa operazione prevede tutte le varianti:
MVI B, dato a 8bit
MVI C, dato a 8bit
MVI L, dato a 8bit
MVI A, dato a 8bit
MVI M, dato a 8bit
La forma generale sarà quindi MVI r, dato a 8bit.
Primo byte: 00DDD1102 (dove al posto di DDD indichiamo il registro di destinazione r o se vogliamo la colonna del set di istruzioni) Secondo byte: dato a 8bit
Istruzioni di movimento ad indirizzamento immediato a tre byte.
Queste istruzioni consentono di caricare le coppie di registri interni (BC, HL, SP che sono a 16bit) con il contenuto del secondo e del terzo byte.Facciamo l’esempio del commando LXI SP, FFFE (dato a 16bit).
Con questo commando si vuole spostare gli 8 bit meno significativi del dato nel registro SPl (cioè la parte meno significativa del registro SP) e gli 8bit più significativi del registro SPh (cioè la parte più significativa del registro SP).
Se la tecnica di memorizzazione segue il format little-endian, allora dobbiamo spezzare l’operazione in tre parti (questo ovviamente sempre perchè il parallelismo del microprocessore è a 8 bit).
Primo byte: LXI SP con codice operazione 31, in binario 001100012
Secondo byte: FE in binario è 111111102 (byte meno significativo dei 16 bit)
Terzo byte: FF in binario 1111111112 (byte più significativo dei 16 bit)
Quinidi il secondo byte (111111102) verrà salvato in SPl, mentre il terzo byte (111111112) verà salvato in SPh.
Ovviamente anche in questo caso esistono le variant: LXI B, dato a 16bit, LXI H dato a 16bit, etc.
Si noti che le precedenti forme sono delle abbreviazioni. Ad esempio LXI B sottointende che si tratti di LXI BC, LXI H sottointende che si tratti di LXI HL, e via dicendo.
Tra le istruzioni di movimento dati ne esistono altre 6.
- LDAX B (a un byte): memorizza nell’accumulatore ACC, il contenuto della locazione di memoria M indirizzata da BC. E’ l’equivalente di MOV A, M;
- STA, indirizzo a 16bit (a tre byte): memorizza il contenuto dell’accumulatore nella locazione M utlizzando come indirizzo la combinazione del secondo e del terzo byte;
- LDA, indirizzo a 16bit (a tre byte): memorizza nell’accumulatore il contenuto della locazione di memoria M indirizzata dalla combinazione del secondo e del terzo byte;
- LHDL, indirizzo a 16bit (a tre byte)): il contenuto della locazione di memoria M indirizzata dalla combinazione tra il secondo e il terzo byte viene memorizzata nel registro L. Tale indirizzo è poi incrementato di 1 ed il contenuto della nuova locazione di memoria è memorizzato nel registro H;
- SHLD, indirizzo a 16bit (a tre byte): il contenuto del registro L è memorizzato nella locazione dimemoria puntata dalla combinazione del scondo e del terzo byte. Tale indirizzo viene incrementato e il contenuto del registro H viene memorizzato nel nuovo indirizzo;
Istruzioni aritmetiche e logiche
Sono le istruzioni che permettono di effettuare operazioni aritmetiche e confronti booleani. E’ il gruppo più vasto di operazioni nel set di istruzioni. Esse coinvolgono il contenuto dei registri di stato.Istruzioni di somma
Esistono due tipi di operazioni ADD e ADC.Sono entrambe operazioni ad un byte.
ADD prende il contenuto di un registro lo somma con il contenuto del registro ACC e il risultato viene posto nello stesso registro ACC.
ADC, invece, somma il contenuto di un registro con ACC e con il flag C del registro di stato (quello del riporto). Il risultato viene posto nell’accumulatore.
Oltre ad ADD e ADC, esistono anche le operazioni ADI e ACI (a due byte).
L’operazione ADI somma al contenuto dell’accumulatore al contenuto della locazione di memoria puntata dal secondo byte.
L’operazione ACI somma il contenuto dell’accumulatore al contenuto della locazione di memoria puntata dal secondo byte e al flag C del registro di stato.
Istruzioni DAD
Permettono di sommare il contenuto delle coppie BC, HL ed SP e salvare il risultato in HL.Ad esempio DAD B effettua la somma tra il contenuto di HL ed il contenuto di BC ed il risultato lo memorizzano in HL.
Istruzioni di sottrazione
Esistono due operazioni SUB e SBB.Sono entrambe ad un byte.
L’operazione SUB effettua una sottrazione del contenuto dell’accumulatore ACC e il contenuto di uno dei registri B, C, H, L, o della locazione di memoria M. Il risultato viene inserito nell’ACC.
L’operazione SBB, invece, effettua una sottrazione del contenuto dell’accumulatore, il contenuto di uno dei registri e il flag C del registro di stato.
Oltre a SUB e SBB, esistono anche SUI e SBI (a due byte).
SUI permette di sottrarre al contenuto dell’accumulatore il contenuto della locazione di memoria indirizzata dal secondo byte. Il risultato viene salvato nell’accumulatore.
SBI, invece, permette di sottrarre al contenuto dell’accumulatore il contenuto della locazione di memoria indirizzata dal secondo byte e il flag C del registro di stato. Il risultato viene salvato nell’accumulatore.
Istruzioni di incremento e decremento.
Sono istruzioni ad un byte che permettono di incrementare/decrementano di 1 i registri B, C, H, L, ACC e della locazione di memoria M. INR r, incrementa di 1 il registro r.DCR r, decrementa di 1 il registro r.
Esistono anche istruzioni di incremento e decremento a due byte: INX e DEX.
INX permette di incrementare di 1 le coppie di registri. Ad esempio INX B, incrementa di 1 i registri BC, INX H, incrementa di 1 i registri HL, etc.
Allo stesso modo DEX decrementa di 1 le coppie di registri. Ad esempio DEX B, decrement di 1 I registri BC, etc).
Istruzioni di confronto
Si utilizzano per confrontare due numeri e si avvalgono del flag C del registro di stato.Effettuano una sottrazione tra il contenuto dell’ACC e il contenuto di un registro (B, C, H, L) o della locazione M. Se il contenuto di ACC è minore del contenuto del registro allora il flag C sarà settato ad 1. Zero altrimenti.
L’operazione è la CMP.
Una seconda operazione di confronto è quella immediate CPI che è a due byte.
Essa effettua la sottrazione tra il contenuto di ACC e il secondo byte.
Istruzioni logiche
Sono le istruzioni che permettono di applicare le operazioni logiche.Prodotto logico AND
ANA (ad un byte) è l’operazione che applica l’AND tra il contenuto dell’accumulatore e quello di uno dei registri interni riportando il risultato dell’operazione all’interno dell’ACC.E’ possibile effettuare anche l’operazione prodotto logico ANI a due byte che effetua l’AND tra il contenuto dell’ACC e il secondo byte.
Somma logica OR
ORA (ad un byte) è l’operazione che applica l’OR tra il contenuto dell’accumulatore ed uno dei registri interni.Una seconda operazione è ORI (a due byte) che permette di applica l’OR tra il contenuto dell’ACC con il secondo byte.
Somma logica esclusiva XOR
L’operazione XAR (ad un byte) permette di applicare lo XOR (l’OR esclusivo) tra il contenuto dell’ACC e il contenuto di uno dei registri interni ponendo il risultato nell’accumulatore ACC.La corrispondente operazione a due byte è XRI che applica lo XOR tra l’accumulatore e il secondo byte.
Istruzioni di rotazione
Sono istruzioni logiche ad un byte che permettono di traslare da destra o da sinistra i bit dell’accumulatore. L’operazione RAL fa uno shif a sinistra dei bit dell’accumulatore e il posto rimasto vuoto del bit meno significato è sostituito con il bit contenuto nel registro di stato C (carry). Il bit rimosso, viene poi salvato in C.RAR, invece, fa lo shift a destra del bit dell’accumulatore liberando il posto del bit più significativo sostituendolo con il bit del registro di stato C (carry). Il bit rimosso poi viene memorizzato in C.
Le istruzioni RLC e RRC sono identiche alle precedenti. L’unica differenza è che non viene inserito il bit del registro di stato C (carry).
In RLC, lo spazio vuoto viene sostituito con il bit più significativo. Mentre in RRC, lo spazio vuoto viene sostituito con il bit meno significativo.
Il bit rimosso, anche in queste operazioni, viene memorizzato nel registro di stato C.
Istruzioni di salto
Consentono di modificare la sequenzialità di esecuzione di un programma.Piuttosto che eseguire l’istruzione successive, si esegue l’istruzione all’indirizzo specificato dal secondo e terzo byte. L’istruzione “JMP, indirizzo a 16 bit” è una istruzione di salto incondizionato. Viene sposato nel PC l’indirizzo dei 16bit (primo e secondo byte) e la prosecuzione del programma riprende dalla locazione di memoria indirizzata dai 16bit.
Chiaramente quando viene effettuato un JMP, il vecchio contenuto del PC viene perse per cui per ritornare all’istruzione precedente è necessario in nuovo JMP.
A differenza di JMP, gli altri salti possibili sono JNZ, JNC, JPO, JP, JZ, JC, JPE e JM che sono salti condizionati perchè il salto è condizionato dal risultato dell’operazione aritmetica o logica. Se tale condizione è verifica, il salto è esattamente quello di JMP altrimenti l’esecuzione procede all’istruzione successiva.
Il comportamento dei salti condizionati è legato al contenuto del registro di stato.
- L’istruzione JNZ viene eseguita soltanto se il flag ZF del registro di stato è uguale a 0 (ZF=0);
- L’istruzione JNC viene eseguita soltanto se il flag di riporto è uguale a 0 (CF=0);
- L’istruzione JPO viene eseguita soltanto se il flag OF è uguale a 0 (OF=0);
- L’istruzione JP viene eseguita soltanto se il flag SF è uguale a 0 (SF=0);
- L’istruzione JZ è eseguita se il flag ZF del registro di stato è uguale a 1 (ZF=1);
- L’istruzione JC viene eseguita se il flag CF è uguale a 1 (CF=1);
- L’istruzione JPE viene eseguita se il flag OF è uguale a 1 (OF=1);
- L’istruzione JM è eseguita se il flag SF è uguale a 1 (SF=1);
| CCC | Condizione | Flag | |
| 000 | NZ | non zero | ZF=0 |
| 001 | Z | zero | ZF=1 |
| 010 | NC | nessun riporto | CF=0 |
| 010 | NC | nessun riporto | CF=0 |
| 011 | C | con riporto | CF=1 |
| 100 | PO | parità dispari | OF=0 |
| 101 | PE | parità pari | OF=1 |
| 110 | P | risultato positivo | SF=0 |
| 111 | M | risultato negativo | SF=1 |
Istruzioni di chiamata a sottoprogrammi
Spesso quando si crea un programma è necessario invocare durante la normale esecuzione del codice dei sottoprogrammi salvati opportunamente all’interno della memoria RAM.Quando il microprocessore esegue una istruzione di chiamata ad un sottoprogramma, deve salvare il contenuto attuale del PC nella parte di RAM chiamata Stack che è indirizzata dallo Stack Pointer (che si decrementa/incrementa in base a se riceve dei dati e se li rimuove).
Quando l’esecuzione del sottoprogramma termina, il microprocessore recupera il vecchio contenuto del PC dallo stack, lo ripristina nel PC e ritorna ad eseguire il programma chiamante.
La chiamata ad un sottoprogramma avviene tramite l’istruzione incondizionata CALL, indirizzo a 16bit (a tre byte). Questa operazione come anticipato salva nello Stack il contenuto del Program Counter, e recupera l’istruzione dalla memoria all’indirizzo composto dalla combinazione del primo e del secondo byte.
Quando viene eseguita la CALL, il byte più significativo del PC viene salvato nel byte più significativo della locazione puntata da SP (SPH) mentre il byte meno significativo di PC viene salvato nel byte meno significativo della locazione puntata da SP (SPL). A questo punto il contenuto di SP viene decrementato di 1.
Fig. 3 - Schema di funzionamento della chiamata a sottoprogramma
Una volta terminata l’esecuzione del sottoprogramma, l’operazione di ritorno che permette di ritornare al programma principale è la RET.
Questa operazione recupera il contenuto del PC salvato nello stack (raggiungibile tramite il registro SP) prima il byte meno significativo, poi il byte più significativo (in base a se è di tipo little-endian o big-endian). Dopodichè viene decrementato lo stesso SP.
Con questo meccanismo viene ripristinato il PC originario e anche SP punterà alla cella di partenza dello Stack.
Chiaramente è possibile anche continuare ad invocare più volte sottoprogrammi annidati fra loro e il meccanismo continuerebbe a funzionare sfruttando tutta la profondità dello Stack.
Esistono anche istruzioni a chiamata condizionata (a tre byte): CNZ, CNC, CPO, CP, CZ, CC, CPE, CM a cui corrispondono le chiamate di ritorno RNZ, RNC, RPO, RP, RZ, RC, RPE, RM.
Istruzioni di manipolazione dello stack dell'I/O e di controllo della macchina
Sono le istruzioni di controllo delle periferiche da parte del microprocessore.Sono divise in quattro gruppi:
- istruzioni di ingresso/uscita (I/O);
- istruzioni di abilitazione o disabilitazione delle interruzioni;
- istruzioni di controllo;
- istruzioni di salvataggio del programma;
Istruzioni di I/O e gestione delle interruzioni esterne
Sono le istruzioni IN e OUT a due byte.Il secondo byte rappresenta la periferica che si vuole abilitare alla lettura del contenuto del bus dei dati. Essendo 8bit possiamo indirizzare ben 256 periferiche diverse.
Nel caso di IN si sta cercando di abilitare la periferica a scrivere sul bus dei dati mentre nel caso di OUT si sta cercando di abiltarla a leggere sul bus dei dati.
L’abilitazione avviene tramite l’invio di opportuni segnali da parte dell’unità di controllo e termporizzazione verso il sistema esterno.
Questo meccanismo può essere anticipato da uno scambio di segnali che fanno da preludio alla comunicazioni tra microprocessore e sistema esterno.
Quando una periferica vuole comunicare con il microprocessore invia una richiesta di interrupt settando INT a 0.
Le operazioni di abilitazione delle richieste di interruzioni sono EI (che abilita la richiesta) o DI (che disabilita la richiesta) entrambi ad un byte.
Istruzioni di controllo
Sono istruzioni che consentono la gestione del programma. La HLT chiude il programma mentre la NOP consente la correzione di eventuali errori.Istruzioni di salvataggio
Sono istruzioni che offrono versatilità e flessibilità alla programmazione.Ad esempio le operazioni SPHL o XHLT (entrambe a due byte) consentono lo scambio tra registri. SPHL consente di copiare il contenuto della SP in HL mentre XHLT consente di scambiare i contenuti di SP e LT.
Tra queste istruzioni compaiono anche PUSH e POP che consentono di spostare dati all’interno dello stack ed estrapolarli.
Ogni volta che viene invocate una PUSH il contenuto di BC o HL viene spostato nello stack e lo SP viene decrementato. Mentre quando viene effettuata una POP viene recuperate il contenuto puntato da SP e spostato in BC o in HL e poi PC viene incrementato.
Metodi di indirizzamento
In base a quanto visto in precedenza, esistono i seguenti metodi di indirizzamento:- a registro (ad un byte): questo tipo di indirizzamento esplicita il registro all’interno del codice operativo ad esempio per CMP r (10111SSS2) dove SSS indica proprio il registro il cui contenuto va sottratto all’accumulatore.
- a registro indiretto (a due byte): in questo tipo di indirizzamento il contenuto su cui operare è indirizzato dall’indirizzo contenuto in una locazione M della memoria a sua volta indirizzato da una coppia di registri interni. Ad esempio CMP M, confronta il valore contenuto nella cella di memoria puntata dall’indirizzo contenuto in M che a sua volta è puntato dalla coppia di registri HL, con l’accumulatore;
- immediate (a uno o due byte): in questo tipo di indirizzamento si utilizza in maniera immediata il valore del secondo byte non come indirizzo ma come dato vero e proprio. Ad esempio CPI dato a 8 bit, confronta il secondo byte con il contenuto dell’accumulatore;
- diretto (a tre byte): in questo caso il secondo ed il terzo byte contengono l’indirizzo della locazione di memoria in cui è contenuto il dato. Ad esempio l’istruzione di movimento STA, indirizzo a 16bit, il secondo ed il terzo byte contengono l’indirizzo della memoria in cui deve essere trasferito il contenuto dell’accumulatore;
- inerente: in questo tipo di indirizzamento l’istruzione non opera nè sul contenuto dei registri, nè sulle locazioni di memoria. Un esempio è il commando HLT che produce la terminazione dell’esecuzione del programma;
Vediamo ora degli esempi di cicli di istruzione completi.
Ciclo istruzione MOV r1 , r2
L’istruzione MOV esegue lo spostamento del contenuto del registro r2 all’interno del registro r1 .
Vediamo quali sono gli stati macchina.
Ciclo di fetch: Viene immesso sul bus degli indirizzi esterno l’indirizzo della memoria presente nel PC (T1), dopodiché viene prelevata dalla memoria RAM l’istruzione a cui punta tale indirizzo e viene salvata nell’Instruction Register (T2). A questo punto l’istruzione viene presa dall’Instruction Register e viene passata all’unità di decodifica e contemporaneamente il PC viene incrementato (T3).
Ciclo di Execute: Il microprocessore è ora pronto per l’esecuzione dell’istruzione in quanto dovrà semplicemente accedere ai due registri interni e utilizzare il registro di appoggio TEMP. Quindi il ciclo di execute prevederà: la memorizzazione del contenuto del registro r2 all’interno di TEMP (T4) e in fine la memorizzazione del contenuto di TEMP nel registro r1 .
Si noti che l’istruzione precedente prevede un solo ciclo macchina in quanto il microprocessore recupererà un valore dalla memoria esterna soltanto una volta.
Fig. 4 - Flusso di esecuzione dell'istruzione MOV r1 , r2
Ciclo istruzione MOV r, M
Tale comando prevede lo spostamento del contenuto della memoria M puntato dal contenuto di HL, nel registro interno r.
Le singole microistruzioni saranno le seguenti:
Ciclo di Fetch. Viene immesso sul bus degli indirizzi esterno l’indirizzo della cella di memoria a cui punta PC (T1), dopodiché viene prelevata l’istruzione contenuta a quell’indirizzo e spostata nel registro interno Instruction Register (T2). L’istruzione viene spostata dall’Instruction Register all’unità di decodifica e il PC viene incrementato (T3).
Ciclo di Execute. Il microprocessore esegue l’istruzione tramite l’unità di controllo e di temporizzazione. Tuttavia c’è da recupeare l’indirizzo della cella di memoria contenente il dato da spostare nel registro interno r. Dunque viene immesso sul bus degli indirizzi esterno, l’indirizzo contenuto nella coppia di registri HL che punta alla cella della memoria M (T1*). Dopodichè viene recuperato il contenuto di M e spostato nel registro r (T2*).
Si noti come in questo caso abbiamo due cicli macchina in quanto per due volte si accede alla memoria esterna. La prima volta per recuperare l’istruzione da eseguire. La seconda volta per recuperare il dato nella locazione di memoria M.
Fig. 5 - Flusso di esecuzione dell'istruzione MOV r, M
Ciclo di istruzione MVI M, dato a 8 bit
Tale comando prevede un movimento dati immediato. Il dato di 8 bit viene memorizzato nella cella di memoria M (puntata cioè dalla coppia di indirizzi HL).
Questa istruzione, a differenza delle precedenti, è a due byte.
Ciclo di Fetch.: viene immesso l’indirizzo contenuto nel PC sul bus degli indirizzi (T1), viene prelevata l’istruzione dalla memoria RAM e memorizzata nell’Instruction Register (T2), l’istruzione dall’Instruction Register passa all’unità di decodifica e il PC viene incrementato (T3).
Ciclo di Execute: essendo questo comando a due byte, è necessario recuperare il secondo byte. Viene immesso sul bus degli indirizzi esterno l’indirizzo contenuto del PC precedentemente incrementato in modo da recuperare il contenuto della cella di memoria successiva (T1*), viene incrementato nuovamente il PC (T2*), il contenuto recuperato dalla memoria viene spostato in TEMP (T3*). A questo punto bisogna effettuare una nuova chiamata alla memoria per individuare la cella della memoria esterna dove andare a salvare il dato. Si immette quindi sul bus degli indirizzi esterno l’indirizzo contenuto nella coppia di registri interna HL (T1**). Dopodiché si immette il contenuto di TEMP sul bus dei dati esterno per salvare il dato nella memoria RAM (2**).
In questo caso gli stati macchina sono otto mentre i cicli macchina sono ben tre essendo che per tre volte indirizziamo la memoria RAM.
Fig. 6 - Flusso di esecuzione dell'istruzione MVI M, dato a 8 bit
Cosa abbiamo imparato da questa lezione
| Conoscenze |
|
| Abilità |
|
| Competenze |
|
Sede legale e operativa
Via Dei Pini, 56
84040, Vallo Scalo (Staz.)
fraz. di Casal Velino, Salerno
Email: [email protected]
PEC: [email protected]