Didattica → Sistemi e Reti → Gestione periferiche di I/O
Una delle principali funzioni del microprocessore è quella di interagire con una varietà di dispotivi periferici di tipo input/output.
Un sensore, una stampante, un monitor sono dispositivi periferici che ricevono ed inviano segnali da e verso il microprocessore. Per questo motivo ogni periferica ha una unità di controllo in grado di decodificare ed interpretare i comandi provenienti dal microprocessore.
Le periferiche possono essere collegate al microprocessore a stella. Questa soluzione è molto efficiente perchè ogni dispositivo può sfruttare la sua connessione per comunicare con il microprocessore ma è però molto costosa e poco modulare in quanto non è facile connettere nuove periferiche.
Una soluzione più vantaggiosa è la party-line.
Essa prevede un bus collegato al microprocessore su cui sono a loro volta collegati tutti i dispositivi. Chiaramente in questo modo quando si vorrà aggiungere un nuovo dispositivo basterà collegarlo al bus. Questa soluzione, per questo motivo, è molto più economica ma purtroppo meno efficiente perchè essendo il bus condiviso c’è necessità di indirizzare e sincronizzare gli accessi al bus causando un rallentamento nella trasmissione perchè al tempo di trasferimento dei dati si sommano i tempi di indirizzamento e assegnazione del bus.
Un microprocessore comunica con le periferiche per mezzo di circuiti integrati programmabili detti unità o interfacce o porte o ingresso/uscita (I/O).
Il microprocessore per poter comunicare con le porte ha a disposizione degli indirizzi che individuano ogni songola porta.
Una porta di input/output può essere realizzata tramite due tecniche:
Vengono predisposti degli indirizzi speciali all’interno della memoria utilizzati esclusivamente per indirizzare le porte I/O.
Inoltre le istruzioni MOV, IN e OUT sono tutte e tre istruzioni che permettono il movimento dati verso e dalla memoria. Questo è sicuramente un vantaggio potendo aumentare l’efficienza del sistema.
Tuttavia questa tecnica presenta degli svantaggi:
Per accedere alle porte si usano le istruzioni dedicate IN e OUT.
IN registro, porta
OUT porta, registro
dove porta è l’indirizzo di I/O della porta e può essere una costante oppure il contenuto del registro DX. Registro, invece, deve essere l’accumulatore AL per porte ad 8 bit oppure AX per le porte a 16 bit.
Lo scambio dati tra microprocessore e periferiche può avvenire in tre modalità:
Il microprocessore scandisce in maniera sequenziale i dispositivi periferici per rilevare le richieste di intervento. Ciò comporta delle ripetute interruzioni nell’esecuzione del programma principale per eseguire controlli sui dispositivi.
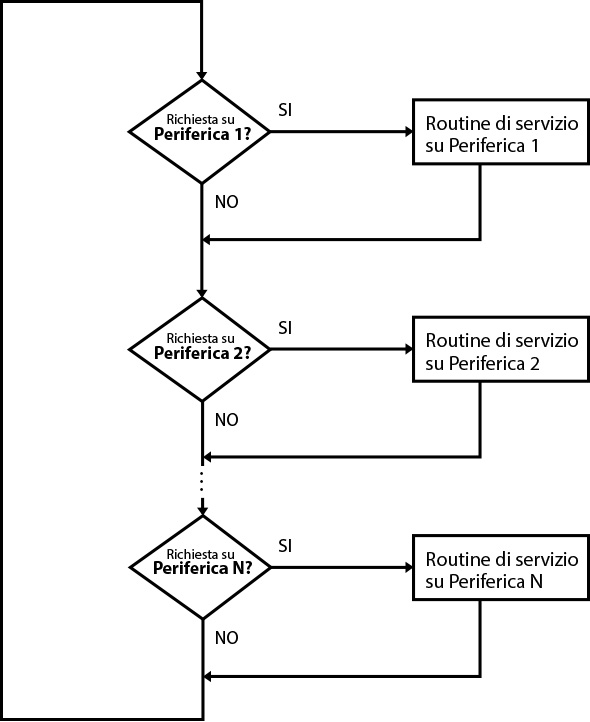
Fig. 1 - Polling
Attraverso dei controlli ripetuti in periodi uguali, viene richiesto al dispositivo se è intenzionato a stabilire una comunicazione con il microprocessore.
L’intervallo di tempo in cui viene effettuato questo controllo, si basa sulla verifica del contenuto di un certo registro X che viene decrementato ad ogni ciclo fetch-execute. Quando il valore contenuto nel registro X raggiunge lo 0, allora viene salvato il contesto minimo nello Stack, viene interrotto il programma principale e inizia il controllo sulle periferiche.
Appena viene rilevato l’interesse da parte di un dispositivo di comunicare (la CPU scandisce dei registri flag associati alle periferiche), avviene il trasferimento delle informazioni attraverso una delle due tecniche di indirizzamento viste in precedenza (memory-mapped I/O o isolated I/O).
Questo metodo di trasferimento ha degli svantaggi:
Dunque il dispositivo I/O invia un segnale asincrono chiamato interrupt (INT) mediante il quale la periferica richiede la connessione.
In questo tipo di trasferimento i dispositivi sono connessi al microprocessore tramite una via comune su cui viaggiano i segnali INT.
Quando il microprocessore riceve il segnale di interrupt, sospende il programma principale copia il PC e il contenuto dei registri interni nello Stack ed esegue il programma di risposta all’interruzione chiamato routine di gestione legata al tipo di interruzione.
Tuttavia qui deve essere utilizzata una ottimizzazione.
Il microprocessore non può perdere troppo tempo nel salvataggio dell’intero “contesto” attuale alla ricezione di un interrupt. Si dovrebbe poter riconoscere quale contesto verrà modificato dalla specifica routine eseguita alla ricezione di un tipo di interrupt.
Esistono quindi tre diversi contesti:
Quando la routine di gestione termina, il microprocessore recupera le informazioni dallo Stack, ricarica il contesto precedente con i valori dei registri interessati dalle modifiche della routine e riprende l’esecuzione del programma principale da dove l’aveva lasciato.
Gli interrupt possono essere di due tipi:
Sorgono a questo punto tre problematiche:
Il primo metodo è puramente software. Tutti i dispositivi sono connessi ad una porta OR all’ingresso del collegamento del segnale INT del microprocessore.
Il microprocessore che riceve questo segnale, avvia una routine attraverso cui controlla i flag di tutti i dispositivi alla ricerca di quello che ha generato l’interrupt per poi procedere con l’esecuzione della richiesta.
Con questa tecnica viene risolto il problema del riconoscimento ed il problema della priorità in quanto la priorità è quella dell'ordine di scansione dei flag delle periferiche da parte del microprocessore.
Il problema della nidificazione invece rimane irrisolto. Infatti se l’interrupt riguarda la richiesta effettuata dal dispositivo tastiera, ad esempio, che è molto lento, succede che possa andare a sovrapporsi ad un precedente interrupt generato invece dal disco che è molto più veloce interrompendolo.
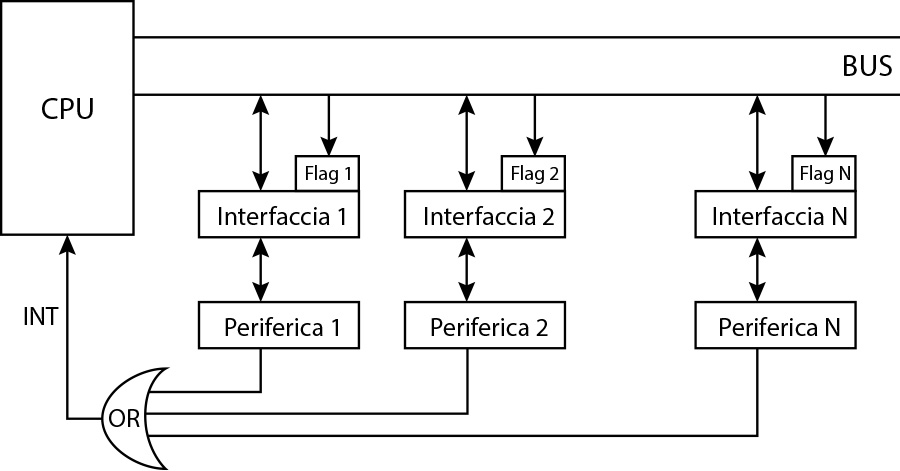
Fig. 2 - Schema di risoluzione di tipo software ai problemi del metodo interrupt
Il secondo metodo è sostanzialmente hardware e prevede l’uso di un circuito integrato chiamato priority encoder con n ingressi (ognuno con una propria priorità stabilita in maniera definitiva e non modificabile) rispettivamente per gli n dispositivi connessi.
Il circuito integrato, avrà un numero di uscite sufficienti a decodificare in binario il numero di ingressi con in più una uscita corrispondente ad un OR collegato al piedino INT del microprocessore.
Ad esempio immaginiamo di avere al più 8 dispositivi. Allora avremo 8 ingressi nel priority encoder. Questo vuol dire che per decodificare il numero dell’ingresso che ha mandato il segnale interrupt (e quindi il dispositivo) ci basteranno 3 bit.
Quando il microprocessore riceve il segnale di interrupt, allora risponderà con il segnale INTA (INTerrupt Acknowledge) verso il priority encoder. Solo a quel punto verrà decodificato il numero dell’ingresso da cui è passato l’interrupt. Se a risultare attivi saranno più ingressi, allora il Priority Encoder, le uscite riporteranno il numero della linea con maggiore priorità.
Questo sistema risolve il problema legato alle richieste multiple in quanto il segnale INTA non verrà generato fino a quando non sarà conclusa l’operazione.
Lo svantaggio è che il problema della priorità è risolto in maniera troppo rigida in quanto vengono assegnate le priorità ai dispositivi in maniera preventiva e non possono essere cambiate in corso (la linea più in alto ha maggiore priorità delle linee più in basso).
Inoltre non è possibile interdire temporaneamente una periferica nell’effettuare richieste di interruzione.
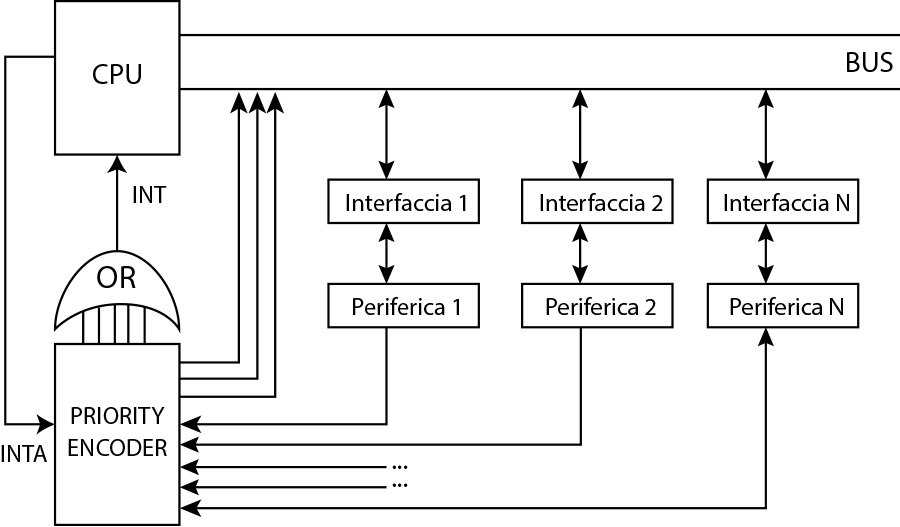
Fig. 3 - Schema di risoluzione di tipo hardware ai problemi del metodo interrupt con l'ausilio del Priority Encoder
Il terzo metodo è una soluzione più flessibile perchè consente di modificare le priorità a seconda delle esigenze. Questa soluzione prevede l’integrazione di un ulteriore circuito integrato detto PIC (Programmable Interrupt Controller).
Il PIC, esattamente come il priority encoder, ha un certo numero di ingressi che chiameremo IRQ (Interrupt ReQuest) la cui priorità è programmabile; possiamo decidere, cioè, se mascherare o meno programmaticamente una linea piuttosto che un’altra.
Il procedimento segue i seguenti passi:
Questa tecnica risolve in maniera efficace i problemi precedentemente elencati.
Infatti è risolto il problema del riconoscimento ed è efficiente nella gestione delle priorità. Inoltre è parzialmente risolto anche il problema delle nidificazioni in quanto il PIC blocca l’invio di ulteriori segnali di interrupt fino a quando quello di massima priorità non ha terminato. Diciamo parzialmente perchè tutti gli interrupt generati a seguito della presa in gestione del precedente interrupt vengono comunque perduti. Esistono situazioni in cui è meglio introdurre anche altri meccanismi.

Fig. 5 - Schema di risoluzione di tipo hardware/software ai problemi del metodo interrupt con l'ausilio del Programmable Interrupt Controller (PIC)
Infatti nel caso in cui il microprocessore riceva un interrupt da parte di un dispositivo I/O, per prima cosa si ha un cambio di contesto. Il contenuto dei registri interni viene copiato nello Stack in memoria, viene indirizzata la locazione di memoria contenente il dato da trasferire. Il dato viene trasferito nell’accumulatore. Dall’accumulatore, il dato viene memorizzato sul dispostivo di I/O (ad esempio la memoria esterna). Viene aggiornato il Program Counter e se il trasferimento è concluso avviene un nuovo cambio di contesto. Viene ripristinato il contenuto dei registri recuperando dallo stack il precedente contesto che permette di riprendere l’esecuzione del programma interrotto. Diversamente se il trasferimento non è concluso, si indirizza la successiva locazione di memoria con il successivo dato da spostare sul dispositivo I/O esterno per riprendere gli ultimi passi.
Quando le operazioni di trasferimento sono molte, chiaramente il microprocessore deve effettuare molte operazioni (essendo master) introducendo inefficienza.
Il trasferimento per accesso diretto alla memoria (Direct Memory Access – DMA) permette di sgravare il processore dal controllo delle operazioni permettendo al dispositivo esterno di dialogare direttamente con la memoria.
Il solo compito assegnato al microprocessore, sarebbe quello di concedere il bus alla periferica che lo gestisce in maniera indipendente.
Il DMA prevede la presenza di un dispositivo speciale che all’occorrenza si trasforma in master e permette il controllo dei dispositivi di I/O. Tale dispositivo programmabile è detto DMAC (DMA Controller).
Un trasferimento dati con questa tecnica prevede i seguenti passi:
Il microprocessore può rilevare la conclusione delle operazioni in due modi:
Fino a quando il DMAC mantiene il segnale BUSR = 0, resta il master nella trasmissione.
Non appena il DMAC disattiva il segnale BUSR = 1, ed invia il segnale INT=0, il microprocessore capisce che la trasmissione è conclusa e può riprendere il ruolo di master e quindi riprendere il controllo del bus disattivando il segnale BUSA.
Da notare che anche il trasferimento di dati da memoria a memoria può essere gestito da un DMAC apportando ulteriore efficienza.
C’è però da gestire il tempo di inoperabilità del microprocessore nel momento in cui viene concesso l’uso del bus al DMAC. Infatti microprocessore e dispositivi I/O non possono accedere contemporaneamente alla memoria e il microprocessore deve attendere la conclusione delle operazioni di trasferimento del dispostivo I/O.
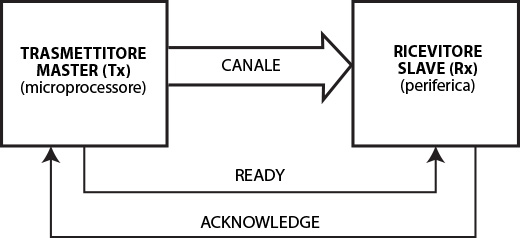
Fig. 6 - Trasmissione asincrona
La trasmissione nella versione asincrona, prevede i seguenti passi:
Il funzionamento della trasmissione nel senso contrario (trasmissione da periferica a microprocessore) è identica.
Nella trasmissione nella versione sincrona, invece, non è necessario da parte del master ricevere il segnale di AKNOWLEDGE in quanto le unità condividono lo stesso clock.
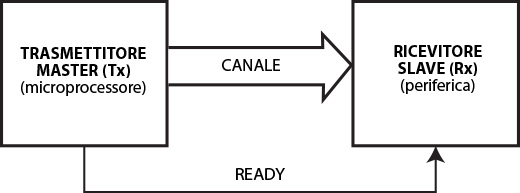
Fig. 7 - Trasmissione sincrona
I passi eseguiti saranno i seguenti:
Nel precedente esempio abbiamo dato per scontato il trasferimento avvenisse su un canale parallelo. E’ possibile prevedere anche la trasmissione su un canale seriale a patto che il master e lo slave si accordino su un bit di inizio (start) e un bit di fine (stop) della sequenza di bit per riconoscere quando i dati da trasmettere sono conclusi. Vediamo in dettagli come questo conflitto può essere risolto. Esistono due modi distinti:
Una possibile alternativa potrebbe essere quella di effettuare un trasferimento di un byte alla volta e quindi ridurre il tempo di inibizione del microprocessore.
Ma anche questa soluzione rallenterebbe troppo la procedura di trasferimento dei dati.
La soluzione più idonea quindi sarebbe quella detta del DMA sovrapposto. Cioè il dispostivo di I/O tiene occupate le risorse comuni soltanto in quegli intervalli in cui il microprocessore non li utilizza.
Indipendentemente dalle tecniche utilizzate, i dati possono essere trasferiti:
Il secondo modo è quello in generale preferibile.
Gestione periferiche di I/O
Una delle principali funzioni del microprocessore è quella di interagire con una varietà di dispotivi periferici di tipo input/output.
Un sensore, una stampante, un monitor sono dispositivi periferici che ricevono ed inviano segnali da e verso il microprocessore. Per questo motivo ogni periferica ha una unità di controllo in grado di decodificare ed interpretare i comandi provenienti dal microprocessore.
Le periferiche possono essere collegate al microprocessore a stella. Questa soluzione è molto efficiente perchè ogni dispositivo può sfruttare la sua connessione per comunicare con il microprocessore ma è però molto costosa e poco modulare in quanto non è facile connettere nuove periferiche.
Una soluzione più vantaggiosa è la party-line.
Essa prevede un bus collegato al microprocessore su cui sono a loro volta collegati tutti i dispositivi. Chiaramente in questo modo quando si vorrà aggiungere un nuovo dispositivo basterà collegarlo al bus. Questa soluzione, per questo motivo, è molto più economica ma purtroppo meno efficiente perchè essendo il bus condiviso c’è necessità di indirizzare e sincronizzare gli accessi al bus causando un rallentamento nella trasmissione perchè al tempo di trasferimento dei dati si sommano i tempi di indirizzamento e assegnazione del bus.
Un microprocessore comunica con le periferiche per mezzo di circuiti integrati programmabili detti unità o interfacce o porte o ingresso/uscita (I/O).
Il microprocessore per poter comunicare con le porte ha a disposizione degli indirizzi che individuano ogni songola porta.
Una porta di input/output può essere realizzata tramite due tecniche:
- I/O mappati come memorie (memory-mapped I/O)
- Ingresso/uscita mappati come I/O (isolated I/O)
MEMORY-MAPPED I/O
In questa tecnica lo spazio di indirizzi tra memoria e porte I/O è lo stesso.Vengono predisposti degli indirizzi speciali all’interno della memoria utilizzati esclusivamente per indirizzare le porte I/O.
Inoltre le istruzioni MOV, IN e OUT sono tutte e tre istruzioni che permettono il movimento dati verso e dalla memoria. Questo è sicuramente un vantaggio potendo aumentare l’efficienza del sistema.
Tuttavia questa tecnica presenta degli svantaggi:
- le locazioni della memoria predisposte per le porte I/O, vanno a ridurre le capacità della memoria nell’utilizzo delle istruzioni e dei dati;
- aumentano i tempi di indirizzamento delle porte in quanto in questa tecnica occorrono solitamente tre byte a differenza dell’uso di istruzioni di I/O dedicate in cui si ha bisogno di soltanto due;
ISOLATED I/O
Memoria e dispositivi di I/O sono separati e la comunicazione tra quest’ultimi e il microprocessore avviene tramite istruzioni di ingresso ed uscita dedicate (IN e OUT). In questa tecnica il microprocessore invia segnali di controllo sul bus di sistema per definire se l’operazione è una comunicazione per dispositivi I/O oppure per la memoria (IO/M). Il vantaggio in questa tecnica è che per indirizzare le porte I/O è richiesto un numero minore di bit con costo minore da parte dell’hardware nel decodificare le istruzoni essendo esse distinte da quelle riferite alla memoria. Inoltre non si ha spreco di memoria.Per accedere alle porte si usano le istruzioni dedicate IN e OUT.
IN registro, porta
OUT porta, registro
dove porta è l’indirizzo di I/O della porta e può essere una costante oppure il contenuto del registro DX. Registro, invece, deve essere l’accumulatore AL per porte ad 8 bit oppure AX per le porte a 16 bit.
MODALITA’ DI TRASFERIMENTO
Esiste un secondo problema, oltre all’indirizzamento. Il problema della sincronizzazione. Come fanno microprocessore e dispositivi I/O a sincronizzarsi per comunicare?Lo scambio dati tra microprocessore e periferiche può avvenire in tre modalità:
- trasferimento programmato (polling);
- trasferimento su interruzione;
- trasferimento per accesso diretto in memoria (DMA);
Trasferimento programmato (polling oppure attesa attiva)
In questa modalità lo scambio dei dati è gestito unicamente dal microprocessore.Il microprocessore scandisce in maniera sequenziale i dispositivi periferici per rilevare le richieste di intervento. Ciò comporta delle ripetute interruzioni nell’esecuzione del programma principale per eseguire controlli sui dispositivi.
Fig. 1 - Polling
Attraverso dei controlli ripetuti in periodi uguali, viene richiesto al dispositivo se è intenzionato a stabilire una comunicazione con il microprocessore.
L’intervallo di tempo in cui viene effettuato questo controllo, si basa sulla verifica del contenuto di un certo registro X che viene decrementato ad ogni ciclo fetch-execute. Quando il valore contenuto nel registro X raggiunge lo 0, allora viene salvato il contesto minimo nello Stack, viene interrotto il programma principale e inizia il controllo sulle periferiche.
Appena viene rilevato l’interesse da parte di un dispositivo di comunicare (la CPU scandisce dei registri flag associati alle periferiche), avviene il trasferimento delle informazioni attraverso una delle due tecniche di indirizzamento viste in precedenza (memory-mapped I/O o isolated I/O).
Questo metodo di trasferimento ha degli svantaggi:
- abbiamo un elevato tempo di elaborazione in quanto il microprocessore deve controllare in continuazione lo stato delle periferiche;
- poco efficiente per le periferiche veloci come il video o la tastiera che devono essere servite in tempo reale e monitorare in sequenza uno dopo l’altro i dispositivi rallenterebbe di molto il trasferimento;
Trasferimento su interruzione (interrupt)
La soluzione consiste nel fare in modo che sia il dispositivo ad informare la CPU di quando ha necessità di stabilire una comunicazione. In questo modo il microprocessore è libero di eseguire le istruzioni senza doverle interrompere per effettuare il polling.Dunque il dispositivo I/O invia un segnale asincrono chiamato interrupt (INT) mediante il quale la periferica richiede la connessione.
In questo tipo di trasferimento i dispositivi sono connessi al microprocessore tramite una via comune su cui viaggiano i segnali INT.
Quando il microprocessore riceve il segnale di interrupt, sospende il programma principale copia il PC e il contenuto dei registri interni nello Stack ed esegue il programma di risposta all’interruzione chiamato routine di gestione legata al tipo di interruzione.
Tuttavia qui deve essere utilizzata una ottimizzazione.
Il microprocessore non può perdere troppo tempo nel salvataggio dell’intero “contesto” attuale alla ricezione di un interrupt. Si dovrebbe poter riconoscere quale contesto verrà modificato dalla specifica routine eseguita alla ricezione di un tipo di interrupt.
Esistono quindi tre diversi contesti:
- contesto minimo: che è quello che verrà sicuramente modificato durante l’esecuzione di una qualsiasi routine;
- contesto specifico: ciò che viene effettivamente modificato da una particolare routine;
- contesto invariante: tutto ciò che fa parte del contesto attuale ma che non viene modificato dalla routine;
Quando la routine di gestione termina, il microprocessore recupera le informazioni dallo Stack, ricarica il contesto precedente con i valori dei registri interessati dalle modifiche della routine e riprende l’esecuzione del programma principale da dove l’aveva lasciato.
Gli interrupt possono essere di due tipi:
- interrupt esterni (o hardware): sono generati dai dispositivi esterni verso il microprocessore;
- interrupt interni (o software): sono generati attraverso l’esecuzione di specifiche operazioni come INT XXX oppure CALL XXX. Di solito vengono chiamate per accedere direttamente alle risorse del sistema operativo;
Sorgono a questo punto tre problematiche:
- Problema del riconoscimento: se più dispositivi condividono l’unico accesso, come fa il microprocessore a sapere chi ha lanciato l’interrupt?
- Problema delle richieste multiple e priorità: se arrivano in contemporanea due interrupt quale dei due viene servito per prima?
- Problema delle interruzioni nidificate: mentre è in esecuzione una ISR (Instruction Service Routine) cosa succede se ne arriva un’altra?
Il primo metodo è puramente software. Tutti i dispositivi sono connessi ad una porta OR all’ingresso del collegamento del segnale INT del microprocessore.
Il microprocessore che riceve questo segnale, avvia una routine attraverso cui controlla i flag di tutti i dispositivi alla ricerca di quello che ha generato l’interrupt per poi procedere con l’esecuzione della richiesta.
Con questa tecnica viene risolto il problema del riconoscimento ed il problema della priorità in quanto la priorità è quella dell'ordine di scansione dei flag delle periferiche da parte del microprocessore.
Il problema della nidificazione invece rimane irrisolto. Infatti se l’interrupt riguarda la richiesta effettuata dal dispositivo tastiera, ad esempio, che è molto lento, succede che possa andare a sovrapporsi ad un precedente interrupt generato invece dal disco che è molto più veloce interrompendolo.
Fig. 2 - Schema di risoluzione di tipo software ai problemi del metodo interrupt
Il secondo metodo è sostanzialmente hardware e prevede l’uso di un circuito integrato chiamato priority encoder con n ingressi (ognuno con una propria priorità stabilita in maniera definitiva e non modificabile) rispettivamente per gli n dispositivi connessi.
Il circuito integrato, avrà un numero di uscite sufficienti a decodificare in binario il numero di ingressi con in più una uscita corrispondente ad un OR collegato al piedino INT del microprocessore.
Ad esempio immaginiamo di avere al più 8 dispositivi. Allora avremo 8 ingressi nel priority encoder. Questo vuol dire che per decodificare il numero dell’ingresso che ha mandato il segnale interrupt (e quindi il dispositivo) ci basteranno 3 bit.
Quando il microprocessore riceve il segnale di interrupt, allora risponderà con il segnale INTA (INTerrupt Acknowledge) verso il priority encoder. Solo a quel punto verrà decodificato il numero dell’ingresso da cui è passato l’interrupt. Se a risultare attivi saranno più ingressi, allora il Priority Encoder, le uscite riporteranno il numero della linea con maggiore priorità.
Questo sistema risolve il problema legato alle richieste multiple in quanto il segnale INTA non verrà generato fino a quando non sarà conclusa l’operazione.
Lo svantaggio è che il problema della priorità è risolto in maniera troppo rigida in quanto vengono assegnate le priorità ai dispositivi in maniera preventiva e non possono essere cambiate in corso (la linea più in alto ha maggiore priorità delle linee più in basso).
Inoltre non è possibile interdire temporaneamente una periferica nell’effettuare richieste di interruzione.
Fig. 3 - Schema di risoluzione di tipo hardware ai problemi del metodo interrupt con l'ausilio del Priority Encoder
Il terzo metodo è una soluzione più flessibile perchè consente di modificare le priorità a seconda delle esigenze. Questa soluzione prevede l’integrazione di un ulteriore circuito integrato detto PIC (Programmable Interrupt Controller).
Il PIC, esattamente come il priority encoder, ha un certo numero di ingressi che chiameremo IRQ (Interrupt ReQuest) la cui priorità è programmabile; possiamo decidere, cioè, se mascherare o meno programmaticamente una linea piuttosto che un’altra.
Il procedimento segue i seguenti passi:
- una periferica segnala la richiesta di servizio al PIC;
- se l’ingresso di quella periferica non è mascherato e non vi sono altre richieste di priorità superiore pendenti, il PIC inoltra la richiesta sulla linea INT;
- la CPU riceve il segnale sulla linea INT e invia il segnale di INTA che stabilisce l’accettazione della richiesta;
- il PIC riceve il segnale INTA, genera un codice di interruzione che invia alla CPU immettendolo sul bus dei dati;
- la CPU riceve tale codice di interruzione tramite il quale riconosce il dispositivo che ha generato l’interrupt e determina l’indirizzo della routine ISR (Interrupt Service Routine) associato alla gestione della periferica per mandarla in esecuzione. Per fare ciò il microprocessore ricorre ad una tabella di sistema detta tabella dei vettori allocata a partire dall’indirizzo di memoria 0000:0000. Ogni elemento della tabella è un vettore ed è costituito da quattro byte che rappresentano l’indirizzo di partenza completo della ISR (2 byte per il segmento e 2 byte per l’offset);
Questa tecnica risolve in maniera efficace i problemi precedentemente elencati.
Infatti è risolto il problema del riconoscimento ed è efficiente nella gestione delle priorità. Inoltre è parzialmente risolto anche il problema delle nidificazioni in quanto il PIC blocca l’invio di ulteriori segnali di interrupt fino a quando quello di massima priorità non ha terminato. Diciamo parzialmente perchè tutti gli interrupt generati a seguito della presa in gestione del precedente interrupt vengono comunque perduti. Esistono situazioni in cui è meglio introdurre anche altri meccanismi.
Fig. 5 - Schema di risoluzione di tipo hardware/software ai problemi del metodo interrupt con l'ausilio del Programmable Interrupt Controller (PIC)
Trasferimento per accesso diretto in memoria (DMA)
Nei metodi di trasferimento visti in precedenza, il microprocessore si comporta da master e i dispositivi esterni da slave. Ciò vuol dire che il microprocessore ha un ruolo centrale nel trasferimento di informazioni. Putroppo nei casi in cui si hanno numerose richieste di accesso ai dispositivi esterni di I/O, il carico di gestione del microprocessore cresce rendendo le operazioni poco efficienti.Infatti nel caso in cui il microprocessore riceva un interrupt da parte di un dispositivo I/O, per prima cosa si ha un cambio di contesto. Il contenuto dei registri interni viene copiato nello Stack in memoria, viene indirizzata la locazione di memoria contenente il dato da trasferire. Il dato viene trasferito nell’accumulatore. Dall’accumulatore, il dato viene memorizzato sul dispostivo di I/O (ad esempio la memoria esterna). Viene aggiornato il Program Counter e se il trasferimento è concluso avviene un nuovo cambio di contesto. Viene ripristinato il contenuto dei registri recuperando dallo stack il precedente contesto che permette di riprendere l’esecuzione del programma interrotto. Diversamente se il trasferimento non è concluso, si indirizza la successiva locazione di memoria con il successivo dato da spostare sul dispositivo I/O esterno per riprendere gli ultimi passi.
Quando le operazioni di trasferimento sono molte, chiaramente il microprocessore deve effettuare molte operazioni (essendo master) introducendo inefficienza.
Il trasferimento per accesso diretto alla memoria (Direct Memory Access – DMA) permette di sgravare il processore dal controllo delle operazioni permettendo al dispositivo esterno di dialogare direttamente con la memoria.
Il solo compito assegnato al microprocessore, sarebbe quello di concedere il bus alla periferica che lo gestisce in maniera indipendente.
Il DMA prevede la presenza di un dispositivo speciale che all’occorrenza si trasforma in master e permette il controllo dei dispositivi di I/O. Tale dispositivo programmabile è detto DMAC (DMA Controller).
Un trasferimento dati con questa tecnica prevede i seguenti passi:
- il dispositivo I/O segnala la propria disponibilità alle operazioni di trasferimento al DMAC attraverso il segnale DRQ (DMA ReQuest). Nel caso siano presenti più richieste vengono soddisfatte una alla volta secondo la priorità assegnata forzando nello stato di attesa le altre;
- il DMAC, alla ricezione del DRQ, invia al microprocessore il segnale BUSR = 0 tramite il quale lo informa dell’intenzione da parte di un dispositivo di richiedere la concessione del bus per un trasferimento di dati;
- il microprocessore quando trova attivo il segnale BURS, può rispondere o rifiutando con l’invio del segnale BUSA (BUS Aknowledge) settato a 1 oppure può accettare settandolo a 0 e inizializzando alcuni registri del DMAC che contengono:
l’indirizzo della periferica selezionata;
il tipo di operazione da compiere (il senso di trasferimento);
l’indirizzo della prima locazione di memoria interessata al trasferimento;
il numero di byte da trasferire;
La presenza di questi registri all’interno del DMAC è giustificata dal fatto che le operazioni di trasferimento non sono più affidate al microprocessore e quindi ai suoi registri interni. Si noti che essendo che nel trasferimento non abbiamo più le fasi di fetch, decode ed execute, l’istruzione di salvataggio di ogni segmento di dato avviene in un solo ciclo di clock; - la CPU si preoccupa a questo punto di porre tutti i suoi collegamenti al bus in alta impedenza;
- A quel punto il DMAC può fare due cose:
a. Prende in carico il trasferimento applicando una trasmissione sequenziale che prevede il savataggio del dato dalla memoria centrale ai propri registri sul canale del dispositivo che fa richiesta. Dopodichè lo spostamento dei dati dai registri al dispositivo; b. invia al dispositivo richiedente il segnale DACK = 1 per informarlo della possibilità di effettuare il trasferimento adottando la tecnica di trasferimento simultaneo durante il quale non vengono usati i registri ma è stesso il dispositivo ad usare i bus e trasferire i dati dalla memoria al dispositivo stesso; - Il microprocessore si scollega logicamente dal resto del sistema;
Il microprocessore può rilevare la conclusione delle operazioni in due modi:
- leggendo ad ogni trasferimento lo stato del DMAC. In questo caso il programma principale esegue in continuazione soltanto un loop di attesa;
- utilizzando gli interrupt: al termine del trasferimento il DMAC invia al microprocessore una richiesta di interrupt (INT=0) che segnala la conclusione delle operazioni;
Fino a quando il DMAC mantiene il segnale BUSR = 0, resta il master nella trasmissione.
Non appena il DMAC disattiva il segnale BUSR = 1, ed invia il segnale INT=0, il microprocessore capisce che la trasmissione è conclusa e può riprendere il ruolo di master e quindi riprendere il controllo del bus disattivando il segnale BUSA.
Da notare che anche il trasferimento di dati da memoria a memoria può essere gestito da un DMAC apportando ulteriore efficienza.
C’è però da gestire il tempo di inoperabilità del microprocessore nel momento in cui viene concesso l’uso del bus al DMAC. Infatti microprocessore e dispositivi I/O non possono accedere contemporaneamente alla memoria e il microprocessore deve attendere la conclusione delle operazioni di trasferimento del dispostivo I/O.
Tecniche di trasmissione
Esistono due tipologie di trasmissione: in parallelo e seriale. La trasmissione in parallelo prevede tanti collegamenti per quanti sono i bit che costituiscono la parola. Quindi n bit, n collegamenti. Questo garantisce l’inivio di n bit in maniera simultanea. La trasmissione seriale invece, prevede soli due collegamenti: uno di invio e uno di ricezione. Su questi collegamenti i bit vengono spediti uno dietro l’altro in maniera sequenziale. Chiaramente la variante parallela è n volte più volece rispetto alla versione seriale. Tuttavia la trasmissione parallela è più costosa in quanto è necessario avere molti collegamenti. E questo costo è tanto più elevato quanto maggiori sono le distanze tra unità di controllo e dispositivi. Quindi quando le distanze sono notevoli e in genere quando i dispositivi sono già lenti di per se conviene utilizzare collegamenti seriali. Esiste un’altra distinzione tra tipi di trasmissione:- trasmissione sincrona: è quando le unità interessate al trasferimento sono sincronizzate sullo stesso intervallo temporale clock;
- trasmissione asincrona: è quando ogni unità ha il suo personale clock e quindi non è richiesto il sincronismo;
Fig. 6 - Trasmissione asincrona
La trasmissione nella versione asincrona, prevede i seguenti passi:
- il master (Tx) invia un segnale di READY alla periferica (Rx) per informarla dell’intenzione da parte del master di inviare dati;
- la periferica, ricevuto il segnale READY, risponde con un AKNOWLEDGE per informare il master che è pronto a ricevere. Fino a quando il segnale AKNOWLEDGE è attivo, il master non può compiere operazioni;
- La periferica segnala al master la fine della lettura dei dati disattivando il segnale AKNOWLEDGE (che vale come conferma di avvenuta ricezione);
- Il master disattiva il segnale READY;
Il funzionamento della trasmissione nel senso contrario (trasmissione da periferica a microprocessore) è identica.
Nella trasmissione nella versione sincrona, invece, non è necessario da parte del master ricevere il segnale di AKNOWLEDGE in quanto le unità condividono lo stesso clock.
Fig. 7 - Trasmissione sincrona
I passi eseguiti saranno i seguenti:
- Il master invia il segnale READY allo slave;
- Il master non attende il segnale di risposta dello slave, ma invia immediatamente i dati ad intervalli scanditi dal clock;
- Il master di tanto in tanto reinvia il segnale READY per evitare che le due unità perdano il sincronismo;
Nel precedente esempio abbiamo dato per scontato il trasferimento avvenisse su un canale parallelo. E’ possibile prevedere anche la trasmissione su un canale seriale a patto che il master e lo slave si accordino su un bit di inizio (start) e un bit di fine (stop) della sequenza di bit per riconoscere quando i dati da trasmettere sono conclusi. Vediamo in dettagli come questo conflitto può essere risolto. Esistono due modi distinti:
- Il microprocessore si inibisce durante il periodo di trasferimento del dato da parte del dispositivo (che detiene il controllo tramite la DMAC del bus dei dati e degli indirizzi);
- Il microprocessore non si inibisce ma il dispositivo I/O sfrutta, per il trasferimento dei dati, gli intervalli di tempo in cui il microprocessore non effettua accessi alla memoria;
Una possibile alternativa potrebbe essere quella di effettuare un trasferimento di un byte alla volta e quindi ridurre il tempo di inibizione del microprocessore.
Ma anche questa soluzione rallenterebbe troppo la procedura di trasferimento dei dati.
La soluzione più idonea quindi sarebbe quella detta del DMA sovrapposto. Cioè il dispostivo di I/O tiene occupate le risorse comuni soltanto in quegli intervalli in cui il microprocessore non li utilizza.
Indipendentemente dalle tecniche utilizzate, i dati possono essere trasferiti:
- un byte per volta (byte by byte): come abbiamo visto in precedenza;
- a pacchetti di byte (burst): il DMAC, dopo aver trasferito il primo byte, prima di rilasciare le risorse si accerta se esistono altri byte disponibili da trasferire. Se ci sono effettua il trasferimento, altrimenti rilascia le risorse al microprocessore;
- in modo continuo: il bus viene rilasciato solo quanto tutta l’operazione di trasmissione è conclusa.
Il secondo modo è quello in generale preferibile.
Cosa abbiamo imparato da questa lezione
| Conoscenze |
|
| Abilità |
|
| Competenze | Nessuna competenza in particolare |
Sede legale e operativa
Via Dei Pini, 56
84040, Vallo Scalo (Staz.)
fraz. di Casal Velino, Salerno
Email: [email protected]
PEC: [email protected]