Didattica → Sistemi e Reti → Architetture non Von Neumann
Le architetture RISC si basano sul concetto di Pipeline.
Immaginiamo l’esempio di una lavanderia. Un processo normale prevederebbe i seguenti passi:
Questo processo non è del tutto ottimizzato in quanto si potrebbe pensare di mettere in funzione la lavatrice per un secondo carico al punto 2 e velocizzare le operazioni. In questo modo si ottiene una esecuzione del processo in parallelo.>
Questo è il prinicipio alla base della produzione industriale.
Lo stesso principio viene applicato ai processori e tale approccio è detto pipeline.>
Mentre nelle architetture CISC le operazioni sono sequenziali e quindi soltanto quando un’istruzione è completamente eseguita può iniziare quella successiva, in RISC viene applicato l’approccio su pipeline.>
Generalmente l’esecuzione di una istruzione prevede 5 passi:
La pipeline per parallelizzare queste microistruzioni, dovrà essere strutturata in 5 stati come è visibile dalle seguente figura (Fig. 1).
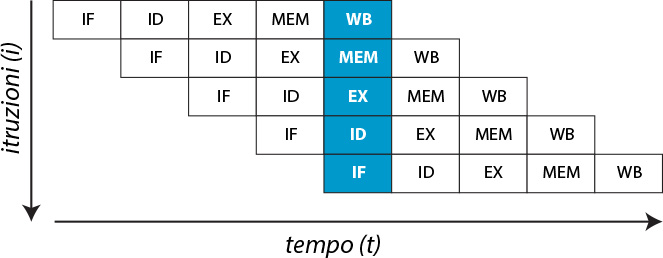
Fig. 1 - Pipeline
Sull’asse delle ascisse vediamo il tempo t e sull’asse delle ordinate le istruzioni i.
La differenza architetturale rispetto a CISC sta nel fatto che il microprocessore con pipeline ha a disposizione unità ognuna predisposta all’operazione di uno stadio. E questo permette quindi il parallelismo. Seguendo l’analogia della lavanderia è come se predisponessimo per ogni attività un dipendente che si occupa solo di quella mansione.
Quando il microprocessore con pipeline parte con l’esecuzione inizialmente non ha il suo pieno beneficio in termini di parallelismo. Bisogna attendere il quinto stadio perchè il microprocessore vada a regime. Da quello stadio in poi ad ogni ciclo di clock il microprocessore completa una istruzione quintuplicando quindi le sue performance.
Va detto che una architettura con pipeline è più complessa dal punto di vista circuitale rispetto ad un’architettura non pipeline.
L'obiettivo dei progettisti era quello di:
A differenza delle architetture CISC, nelle architetture RISC ogni registro può essere utilizzato come sorgente e come destinazione di qualsiasi istruzione.
Questa flessibilità è detta ortogonalità del set di istruzioni che rende i programmi più compatti.
Un’altra caratteristica delle architetture RISC è l’esecuzione condizionata che permette di evitare i salti che in CISC causano un cambio di contesto che rallenta di molto le prestazioni.
La pipeline e le architetture RISC sembrano essere delle soluzioni eccellenti in quanto a performace ed in effetti lo sono. Tuttavia non sempre è possibile ottenere il massimo grado di ottimizzazione dell’esecuzione delle istruzioni. Ciò dipende dal fatto che le singole microistruzioni possono essere parallelizzate se non hanno dipendenze fra di loro. In altre parole una microistruzione è parallelizzabile se la sua esecuzione non prevede di operare sul risultato dell’esecuzione della precedente microistruzione. In tal caso lo stadio che esegue tale microistruzione deve rimanere in attesa che la precedente sia completata inficiandone il parallelismo e rallentando il processo.
Esistono tre tipi di dipendenze:
La dipendenza dei dati si dividono in:
Le dipendenze strutturali invece riguardano la contesa delle risorse hardware. Più istruzioni potrebbero dover utilizzare la medesima risorsa e quindi creare un conflitto da risolvere.
Per risolvere tali dipendenze sono state sviluppate due soluzioni (una software e una hardware):
Facciamo un esempio.
Istruzione 1: r = a + b;
Istruzione 2: s = 2*r;
La seconda istruzione non può leggere l’operando r (nello stadio ID) finchè la prima non produce un risultato per r e lo scrive in uno dei registry interni (stadio WB). In tal caso abbiamo una dipendenza RAW che genera il blocco dell’istruzione 2 nel primo stadio (IF).
Questo produce un blocco dell’istruzione 2 nello stadio IF.

Fig. 2 - Dipendenza strutturale
Nella figura (Fig. 2) è rappresentata schematicamente la pipeline dell’esempio precedente. All’istante t0 parte l’esecuzione del primo stadio di fetch della prima istruzione. All’istante t1, la prima istruzione raggiunge il secondo stadio di decode e parte il fetch della seconda istruzione. All’istante t2 la seconda istruzione resta bloccata nella fase di decode perchè non può decodificare la variabile r e quindi resta bloccata in attesa che la prima istruzione produca un risultato per la variabile r. Quindi la prima istruzione attraversa gli istanti t3 di indirizzamento alla memoria e l’istante t4 di scrittura del dato nel registro. Solo all’istante t5 la seconda istruzione può ripartire. In realtà è ancora possibile fare qualcosa per migliorare le prestazioni della pipeline anche in caso di dipendenze. La tecnica del forwarding path è quello di cui abbiamo bisogno.
Tuttavia si potrebbe fare una osservazione. Affinchè la seconda istruzione riprenda la propria esecuzione non sarebbe necessario che il valore di r sia effettivamente salvato nel registro anche perchè quel valore è già calcolato nella fase execute (stadio EX) dall’esecuzione della prima istruzione.
Per cui basterebbe trovare il modo di passare tale valore alla fase di decode (stadio DE) della seconda istruzione in modo da evitare il blocco.
Questo è possibile prevedendo dei collegamenti tra i vari stadi della pipeline. Così che a conclusione dell’esecuzione della prima istruzione, il valore di r possa essere passato direttamente alla seconda istruzione senza attendere che venga salvato nel registro.
Il più importante microprocessore di tipo RISC è l’ARM basato su una pipeline a 5 stadi grazie alle sue caratteristiche a basso consumo domina il settore dei dispositive mobile.
Oggi giorno tutti i microprocessori sono RISC. Tuttavia esistono anche modelli di processori che pur essendo CISC traducono le istruzioni inernamente in istruzioni RISC. In tal caso l’architettura è detta CRISC.
Le architetture CRISC sono state introdotte per mantenere la compatibilità con i passati programmi con set di istruzioni CISC sfruttando allo stesso tempo i vantaggi in prestazioni dei processor RISC.
La memoria virtuale è necessaria in quanto molto spesso i programmi occupano molto più spazio di quanto ne è disponibile nella memoria centrale ed un programma per essere eseguito deve risiedere per forza nella memoria centrale.
E’ necessario quindi un meccanismo detto di paginazione che consente di superare questo limite.
Per fare questo, un programma è diviso in un definito numero di pezzi detto pagine. Tutti gli indirizzi utilizzati da un programma, in fase di esecuzione, sono definiti spazio di indirizzi virtuali che si distinguono dagli indirizzi fisicamente presenti nella memoria centrale che si riferiscono allo spazio degli indirizzi fisici.
L’indirizzo fisico, corrispondente a ogni indirizzo virtuale, è specificato in una mappa di memoria (o tabella delle pagine) aggiornata continuamente di dimensione 2N dove N è la dimensione di un indirizzo.
Ogni elemento di questa tabella (Page Table Entry) restituisce il numero fisico della pagina corrispondente a quello virtuale che, combinato con l’offset della pagina, forma l’indirizzo fisico completo.
Gli N bit meno significativi dell’indirizzo (l’offset all’interno della pagina) rimangono invariati, mentre i bit più significativi rappresentano il numero della pagina.
Il compito di calcolare l’indirizzo fisico completo a partire dall’indirizzo virtuale, è assegnato alla MMU che generalmente è un dispositivo collocato nel microprocessore.
E’ possibile che non esista memoria fisica (RAM) allocate a una dat pagina virtuale. In questo caso la MMU segnala una condizione di pagina mancante (page fault) al microprocessore. Quando si verifica questa condizione, il Sistema Operativo interviene per trovare una pagina libera nella RAM e di crare una nuova PTE nella quale mappare l’indirizzo virtuale richiesto nell’indirizzo fisico della pagina trovata. Quando non c’è spazio sufficiente nella RAM, viene applicato un algoritmo che prevede di scegliere una pagina di memoria farne una copia sulla memoria di massa e rimpiazzarla con la nuova pagina.
Allo stesso modo quando non ci sono PTE non utilizzate a disposizione, il sistema operative deve liberarne una.
Gli effetti benefici dell’utilizzo della MMU sono legati anche:
Questa tecnica permette di l’esecuzione di programmi di qualsiasi dimensione. In questo modo I programmi possono memorizzare I dati nello spazio di indirizzi virtuali, senza considerare la reale quantità di infirizzi fisici effettivamente presenti in memoria centrale.
Le architetture SISD, prevedono una unità di controllo, una unità esecutiva (Point Execution) ed una sola memoria.
Sono le architetture tradizionali che si basano sul modello di Von Neumann in cui l’esecuzione delle istruzioni è sequenziale sul singolo dato.
Le architetture SIMD, invece, prevedono una sorta di parallelismo sui dati. Infatti possiamo avere una unità di controllo che gestisce uno o più unità esecutive che però eseguono la stessa istruzione su un vettore di dati. Questo consente chiaramente la possibilità di parallelizzare le stesse operazione su un insieme di dati contemporaneamente.
Queste architetture sono particolarmente indicate in ambito multimediale. Ad esempio immaginiamo di voler aggiungere luminosità ad una immagine. Piuttosto che eseguire l’operazione un pixel per volta, eseguiamo la stessa operazione a blocchi di pixel migliorandone l’efficienza.
Le architetture MISD sono quelle basate sulla pipeline dove uno stesso dato attraversa più unità di esecuzione.
Le architetture MIMD, invece, prevedono più unità di esecuzione che eseguono istruzioni differenti su dati differenti.
La differenza di quest’ultima architettura è sostanziale in quanto ogni unità di esecuzione ha la sua memoria. Questa architettura in termini di parallelismo offre ottime prestazioni.
Parallelismo
Il grado massimo di parallelismo di un microprocessore è il numero massimo di bit che esso può elaborare contemporaneamente durante un ciclo di macchina.
Le Architetture non Von Neumann
Architettura di microprocessori
Esistono due tipi di architettura di microprocessori. Quello visto precedentemente chiamato CISC (Complex Instruction Set Computer) che prevede un ampio set di operazioni complesse e complete e un numero ridotto di registri e il RISC (Reduced Instruction Set Computer) che al contrario prevede un set ridotto di operazioni che però a differenza di CISC sono molto più veloci da eseguire e prevedono un basso consumo. Tuttavia mentre in CISC il lavoro del programmatore è facilitato potendo eseguire operazioni complesse con singole istruzioni su un architettura RISC il lavoro del programmatore diventa più ostico avendo a disposizione poche semplici operazioni che, attraverso una loro combinazione, possono coprire tutte il set complete di operazione che un computer può realizzare.Le architetture RISC si basano sul concetto di Pipeline.
Pipeline
Il principio dietro una architettura pipeline è quello della produzione industriale.Immaginiamo l’esempio di una lavanderia. Un processo normale prevederebbe i seguenti passi:
- si predispone il carico nella lavatrice;
- si attende il completamento del processo di lavaggio per poi procedure all’asciugatura;
- completata l’asciugatura si procede con lo stiraggio degli indumenti;
- completato lo stiraggo si pongono gli abiti in un appendi abiti;
Questo processo non è del tutto ottimizzato in quanto si potrebbe pensare di mettere in funzione la lavatrice per un secondo carico al punto 2 e velocizzare le operazioni. In questo modo si ottiene una esecuzione del processo in parallelo.>
Questo è il prinicipio alla base della produzione industriale.
Lo stesso principio viene applicato ai processori e tale approccio è detto pipeline.>
Mentre nelle architetture CISC le operazioni sono sequenziali e quindi soltanto quando un’istruzione è completamente eseguita può iniziare quella successiva, in RISC viene applicato l’approccio su pipeline.>
Generalmente l’esecuzione di una istruzione prevede 5 passi:
- prelievo dell’istruzione da eseguire dalla memoria (Instruction Fetch - IF);
- lettura e decodifica dell’istruzione (Instruction Decode – ID);
- esecuzione dell’istruzione (Execution – EX);
- accesso ad un operando memorizzato nella memoria dati (Memory – MEM);
- scrittura del risultato n un registro (Write Back – WB);
La pipeline per parallelizzare queste microistruzioni, dovrà essere strutturata in 5 stati come è visibile dalle seguente figura (Fig. 1).
Fig. 1 - Pipeline
Sull’asse delle ascisse vediamo il tempo t e sull’asse delle ordinate le istruzioni i.
La differenza architetturale rispetto a CISC sta nel fatto che il microprocessore con pipeline ha a disposizione unità ognuna predisposta all’operazione di uno stadio. E questo permette quindi il parallelismo. Seguendo l’analogia della lavanderia è come se predisponessimo per ogni attività un dipendente che si occupa solo di quella mansione.
Quando il microprocessore con pipeline parte con l’esecuzione inizialmente non ha il suo pieno beneficio in termini di parallelismo. Bisogna attendere il quinto stadio perchè il microprocessore vada a regime. Da quello stadio in poi ad ogni ciclo di clock il microprocessore completa una istruzione quintuplicando quindi le sue performance.
Va detto che una architettura con pipeline è più complessa dal punto di vista circuitale rispetto ad un’architettura non pipeline.
Architettura RISC
Le architetture RISC nascono con l’intendo, quindi, di velocizzare l’elaborazione.L'obiettivo dei progettisti era quello di:
- codificare istruzione di lunghezza fissa in modo da utilizzre meno spazio nella memoria e consentire una decodifica delle istruzioni rapide e semplice;
- metodi di indirizzamento semplici
- poche e semplici istruzioni
- limitati accessi alla memoria (sono previsti un numero di registry maggiore in modo da permettere il salvataggio di dati nei registry più a lungo e limitare gli accessi quindi alla memoria);
- utilizzo della tecnica pipeline
Set di istruzioni
Proprio per ridurre gli accessi alla memoria, nel set di istruzioni di un microprocessore RISC abbiamo solo due istruzioni di accesso alla memoria: LOAD e STORE rispettivamente per leggere e scrivere dati. Tutte le altre istruzioni sono eseguite sui registri interni ottenendo una maggiore velocità ed efficienza. Ad esempio le istruzioni aritmetiche:- ADD R1, R2, R5: addiziona il contenuto del registro 2 e del registro 5 inserendo il risultato nel registro 1;
- MUL R7, R9, R10: moltiplica il contenuto dei registri 9 e 10 ponendo il risultato nel registro 7;
A differenza delle architetture CISC, nelle architetture RISC ogni registro può essere utilizzato come sorgente e come destinazione di qualsiasi istruzione.
Questa flessibilità è detta ortogonalità del set di istruzioni che rende i programmi più compatti.
Un’altra caratteristica delle architetture RISC è l’esecuzione condizionata che permette di evitare i salti che in CISC causano un cambio di contesto che rallenta di molto le prestazioni.
Dipendenze
Non tutto però sembra essere rose e fiori.La pipeline e le architetture RISC sembrano essere delle soluzioni eccellenti in quanto a performace ed in effetti lo sono. Tuttavia non sempre è possibile ottenere il massimo grado di ottimizzazione dell’esecuzione delle istruzioni. Ciò dipende dal fatto che le singole microistruzioni possono essere parallelizzate se non hanno dipendenze fra di loro. In altre parole una microistruzione è parallelizzabile se la sua esecuzione non prevede di operare sul risultato dell’esecuzione della precedente microistruzione. In tal caso lo stadio che esegue tale microistruzione deve rimanere in attesa che la precedente sia completata inficiandone il parallelismo e rallentando il processo.
Esistono tre tipi di dipendenze:
- dipendenze dei dati
- dipendenze di controllo
- dipendenze strutturali
La dipendenza dei dati si dividono in:
- RAW (Read After Write o True Dipendence): l’istruzione deve attendere fino a quando tutti i suoi operandi sono prodotti;
- WAR (Write After Read o Anti Dependence): l’istruzione può scrivere su un registro solo quando nessun’altra istruzione deve ancora leggere il valore corrente;
- WAW (Write After Write p Output Dependence): l’istruzione che deve scrivere su un registro non deve cancellare il valore scritto da quella precedente (è possibile scrivere il nuovo valore solo quando è stato letto precedentemente);
Le dipendenze strutturali invece riguardano la contesa delle risorse hardware. Più istruzioni potrebbero dover utilizzare la medesima risorsa e quindi creare un conflitto da risolvere.
Per risolvere tali dipendenze sono state sviluppate due soluzioni (una software e una hardware):
- metodologia software (o statica): il compilatore quando produce un codice macchina verifica se esistono delle dipendente. Per fare questo però il compilatore deve basarsi sull’architettura della pipeline per calcolare un sufficiente numero di istruzioni NOP (Not OPeration instruction) per eliminare tutte le dipendenze dei dati e di controllo. Lo svantaggio è che un programma compilato per una pipeline potrebbe non essere utilizzabile su un’architettura di pipeline diversa perchè basterebbe uno stadio di differenza per cambiare il computo dei NOP e rendere il programma incompatibile.
- Metodologia hardware (o dinamica – pipeline interlock): tutte le dipendenze vengono controllate e rispettate dal microprocessore che inserisce opportuni tempi di attesa (allo stesso modo dei NOP dei compilatori). A differenza della metodologia software, però, in questa metodologia è garantita la compatibilità di codice in quanto il controllo avviene a livello hardware. Tuttavia occorre prevedere dell’hardware aggiuntivo che occupa spazio e consuma ulteriore energia.
Facciamo un esempio.
Istruzione 1: r = a + b;
Istruzione 2: s = 2*r;
La seconda istruzione non può leggere l’operando r (nello stadio ID) finchè la prima non produce un risultato per r e lo scrive in uno dei registry interni (stadio WB). In tal caso abbiamo una dipendenza RAW che genera il blocco dell’istruzione 2 nel primo stadio (IF).
Questo produce un blocco dell’istruzione 2 nello stadio IF.
Fig. 2 - Dipendenza strutturale
Nella figura (Fig. 2) è rappresentata schematicamente la pipeline dell’esempio precedente. All’istante t0 parte l’esecuzione del primo stadio di fetch della prima istruzione. All’istante t1, la prima istruzione raggiunge il secondo stadio di decode e parte il fetch della seconda istruzione. All’istante t2 la seconda istruzione resta bloccata nella fase di decode perchè non può decodificare la variabile r e quindi resta bloccata in attesa che la prima istruzione produca un risultato per la variabile r. Quindi la prima istruzione attraversa gli istanti t3 di indirizzamento alla memoria e l’istante t4 di scrittura del dato nel registro. Solo all’istante t5 la seconda istruzione può ripartire. In realtà è ancora possibile fare qualcosa per migliorare le prestazioni della pipeline anche in caso di dipendenze. La tecnica del forwarding path è quello di cui abbiamo bisogno.
Forwarding path
Abbiamo visto nell’esempio precedente che l’esecuzione dell’istruzione 2 resta bloccata nella fase di decode in quanto non è ancora diponibile il contenuto della variabile r. Questo comporta una attesa di un tot di istanti prima di poter ripartire. Più precisamente l’esecuzione della seconda istruzione resta bloccata fino a quando l’esecuzione della prima istruzione non effettui la scrittura della variabile r nel registro (stadio WB).Tuttavia si potrebbe fare una osservazione. Affinchè la seconda istruzione riprenda la propria esecuzione non sarebbe necessario che il valore di r sia effettivamente salvato nel registro anche perchè quel valore è già calcolato nella fase execute (stadio EX) dall’esecuzione della prima istruzione.
Per cui basterebbe trovare il modo di passare tale valore alla fase di decode (stadio DE) della seconda istruzione in modo da evitare il blocco.
Questo è possibile prevedendo dei collegamenti tra i vari stadi della pipeline. Così che a conclusione dell’esecuzione della prima istruzione, il valore di r possa essere passato direttamente alla seconda istruzione senza attendere che venga salvato nel registro.
Il più importante microprocessore di tipo RISC è l’ARM basato su una pipeline a 5 stadi grazie alle sue caratteristiche a basso consumo domina il settore dei dispositive mobile.
Oggi giorno tutti i microprocessori sono RISC. Tuttavia esistono anche modelli di processori che pur essendo CISC traducono le istruzioni inernamente in istruzioni RISC. In tal caso l’architettura è detta CRISC.
Le architetture CRISC sono state introdotte per mantenere la compatibilità con i passati programmi con set di istruzioni CISC sfruttando allo stesso tempo i vantaggi in prestazioni dei processor RISC.
Memory Management Unit (MMU)
In un calcolatore esistono memoria centrale e memoria di massa. Esiste una terza tipologia di memoria, la memoria virtuale.La memoria virtuale è necessaria in quanto molto spesso i programmi occupano molto più spazio di quanto ne è disponibile nella memoria centrale ed un programma per essere eseguito deve risiedere per forza nella memoria centrale.
E’ necessario quindi un meccanismo detto di paginazione che consente di superare questo limite.
Per fare questo, un programma è diviso in un definito numero di pezzi detto pagine. Tutti gli indirizzi utilizzati da un programma, in fase di esecuzione, sono definiti spazio di indirizzi virtuali che si distinguono dagli indirizzi fisicamente presenti nella memoria centrale che si riferiscono allo spazio degli indirizzi fisici.
L’indirizzo fisico, corrispondente a ogni indirizzo virtuale, è specificato in una mappa di memoria (o tabella delle pagine) aggiornata continuamente di dimensione 2N dove N è la dimensione di un indirizzo.
Ogni elemento di questa tabella (Page Table Entry) restituisce il numero fisico della pagina corrispondente a quello virtuale che, combinato con l’offset della pagina, forma l’indirizzo fisico completo.
Gli N bit meno significativi dell’indirizzo (l’offset all’interno della pagina) rimangono invariati, mentre i bit più significativi rappresentano il numero della pagina.
Il compito di calcolare l’indirizzo fisico completo a partire dall’indirizzo virtuale, è assegnato alla MMU che generalmente è un dispositivo collocato nel microprocessore.
E’ possibile che non esista memoria fisica (RAM) allocate a una dat pagina virtuale. In questo caso la MMU segnala una condizione di pagina mancante (page fault) al microprocessore. Quando si verifica questa condizione, il Sistema Operativo interviene per trovare una pagina libera nella RAM e di crare una nuova PTE nella quale mappare l’indirizzo virtuale richiesto nell’indirizzo fisico della pagina trovata. Quando non c’è spazio sufficiente nella RAM, viene applicato un algoritmo che prevede di scegliere una pagina di memoria farne una copia sulla memoria di massa e rimpiazzarla con la nuova pagina.
Allo stesso modo quando non ci sono PTE non utilizzate a disposizione, il sistema operative deve liberarne una.
Gli effetti benefici dell’utilizzo della MMU sono legati anche:
- la protezione della memoria in quanto un sistema operativo può usarla per proteggere la memoria da processi erranti impedento a un processo non autorizzato di accedere a locazioni di memoria non autorizzate. Tipicamente il sistema operative assegna ad ogni process oil suo spazio di indirizzamento virtuale;
- il problema della frammentazione: quando dei blocchi precedentemente allocate si liberano, la memoria può diventare frammentata (discontinua) e quindi il blocco più grande di memoria contigua disponibile potrebbe essere molto più ridotto. Con la memoria virtuale blocchi di memoria non contigui possono essere mappati in indirizzi virtuali contigui;
Questa tecnica permette di l’esecuzione di programmi di qualsiasi dimensione. In questo modo I programmi possono memorizzare I dati nello spazio di indirizzi virtuali, senza considerare la reale quantità di infirizzi fisici effettivamente presenti in memoria centrale.
Architetture parallele
Nel 1966 Micheal Flynn descrisse le architetture dei calcolatori suddividendole in:- SISD (Single Instruction Single Data)
- SIMD (Single Instruction Multiple Data)
- MISD (Multiple Instruction Single Data)
- MIMD (Multiple Instruction Multiple Data)
Le architetture SISD, prevedono una unità di controllo, una unità esecutiva (Point Execution) ed una sola memoria.
Sono le architetture tradizionali che si basano sul modello di Von Neumann in cui l’esecuzione delle istruzioni è sequenziale sul singolo dato.
Le architetture SIMD, invece, prevedono una sorta di parallelismo sui dati. Infatti possiamo avere una unità di controllo che gestisce uno o più unità esecutive che però eseguono la stessa istruzione su un vettore di dati. Questo consente chiaramente la possibilità di parallelizzare le stesse operazione su un insieme di dati contemporaneamente.
Queste architetture sono particolarmente indicate in ambito multimediale. Ad esempio immaginiamo di voler aggiungere luminosità ad una immagine. Piuttosto che eseguire l’operazione un pixel per volta, eseguiamo la stessa operazione a blocchi di pixel migliorandone l’efficienza.
Le architetture MISD sono quelle basate sulla pipeline dove uno stesso dato attraversa più unità di esecuzione.
Le architetture MIMD, invece, prevedono più unità di esecuzione che eseguono istruzioni differenti su dati differenti.
La differenza di quest’ultima architettura è sostanziale in quanto ogni unità di esecuzione ha la sua memoria. Questa architettura in termini di parallelismo offre ottime prestazioni.
Parallelismo
Il grado massimo di parallelismo di un microprocessore è il numero massimo di bit che esso può elaborare contemporaneamente durante un ciclo di macchina.
Immaginiamo di avere una struttura SIMD con quattro unità di elaborazione con pipeline a cinque stadi e una capacità di elaborazione di 64 bit.
Allora il parallelismo totale sarà pari a:
numero_bit_elaborati_contemporaneamente = lunghezza_de_dato*numero_unità_di_elaborazione * numero_degli_stadi_pipeline = 64*5*4 = 1280
Il parallelismo totale, in questo esempio, sarà pari a 1280. Cioè il microprocessore sarà in grado di elaborare in contemporanea 1280 bit.
Se pensiamo però al fatto che nella pipeline non tutti gli stadi lavorano sempre in contemporanea (sia per il fatto che servono un pò di stadi per entrare a regime e sia considerando le dipendenze) il parallelismo totale non coincide con quello reale.
Sia i un certo ciclo di clock, allora vale che:

dove P è il grado di parallelismo totale calcolato in precedenza e Pi è il parallelismo al ciclo di clock i-esimo.
Tuttavia possiamo calcolare il grado di parallelismo medio sommando il parallelismo ottenuto su un certo numero di cicli di clock ad esempio n. Ottenendo:

Calcolato il grado di parallelismo medio possiamo calcolare il tasso di utilizzo come il rapporto tra il parallelismo medio su n cicli di clock e il parallelismo massimo:

Il grado massimo di parallelismo si ottiene moltiplicando la lunghezza delle word impiegate dal microprocessore per la lunghezza del bit slice.
Il bit slice è il numero di bit ottenuto estrando un dato bit in una stessa posizione tra tutte le parole che vengono elaborate contemporaneamente.
Nell’esempio precedente il bit slice m è, essendo le unità di esecuzione 4 e gli stadi della pipeline 5, pari a 20 (5*4). La dimensione delle word n è di 64 bit. Quindi il massimo grado di parallelismo è:

Processore superscalare
Il parallelismo può essere presente in due forme principali: a livello di istruzione e a livello di processore.
Entrambe gli approcci hanno dei vantaggi.
Nel primo caso il parallelismo è sfruttato all’interno delle singole istruzioni in modo tale da permettere ad un processore di elaborarne un maggior numero al secondo.
Nel secondo caso abbiamo più microprocessori che lavorano congiuntamente su uno stesso problema.
Generalmente un processore superscalare è un processore che è in grado di eseguire più di una istruzione per ciclo di clock.
Questi processori sono composti da più unità funzionali dello stesso tipo. Ad esempio possono essere presenti più unità di calcolo ALU.
Un primo approccio prevede una sola pipeline a cui sono associate più unità funzionali.
Come mostrato nel seguente schema (Fig. 3).
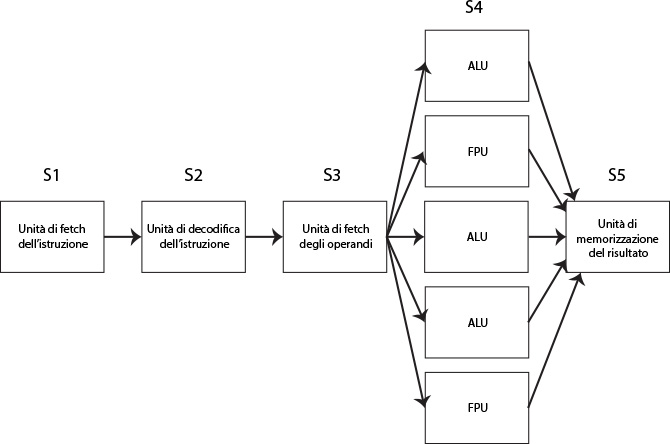
Fig. 3 - Processore superscalare primo approccio
Essendo che lo stadio S4 richiede un tempo di eleborazione maggiore dello stadio S3 (avendo più unità funzionali), si possono parallelizzare le operazioni di calcolo.
Un altro approccio è quello di prevedere più pipeline.
Le unità di controllo vanno a stabilire quali istruzioni possono essere eseguite in parallelo e direzionarle alle rispettive unità.
In questo modo è possibile integrare più pipeline che funzionano in parallelo.
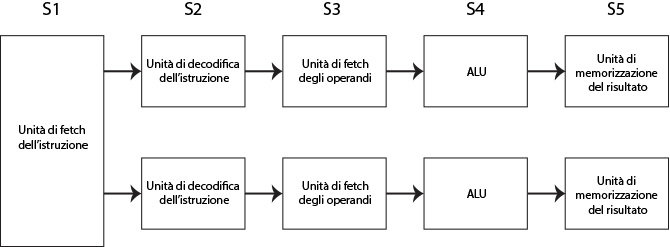
Fig. 4 - Processore superscalare secondo approccio
Allo stadio S1 l’unità di controllo legge le istruzioni e le distribuisce sulle due line in modo da parallelizzare la loro esecuzione.
Questa operazione è molto complessa perchè potrebbe capitare che l’esecuzione di una istruzione richieda come operando l’output di un’altra esecuzione.
L’esecuzione parallela delle istruzioni, richiede inoltre che l’accesso alle risorse condivise (ad esempio la memoria) non deve creare conflitti.
Una alternativa per implementare un processore superscalare, è quello dei core cioè all’interno della stessa CPU, avremo più singoli processori indipendenti tra di loro. Ogni core ha la sua pipeline e l’insieme delle pipeline sono separate tra loro. Questo permette di eseguire programmi diversi contemporaneamente.
In generale la soluzione multicore è preferibile rispetto alla soluzione di avere più pipeline che condividono risorse in quanto all’aumentare delle pipeline aumenta il rischio di conflitti.
Di contro, prediligere una architettura multicore complica la parte software in quanto prevede conoscenze in programmazione multithreading per sfruttare la massimo il parallelismo.
Prestazioni migliori in termini di parallelismo si possono ottenere in contesti in cui è necessario eseguire stesse istruzioni su molti dati.
Per ottenere questo, si utilizzano i così detti processori vettoriali o array processor.
Processore vettoriale
Un processore vettoriale è un processore con una unità di controllo e n processori che ricevono in broadcast dall’unità di elaborazione la stessa istruzione ed elaborano in maniera parallela utilizzando dati provenienti dalla propria memoria. Tali processori sono anche detti SIMD (Single Instruction Multiple Data).
I processori paralleli sono comuni nelle applicazioni scientifiche.
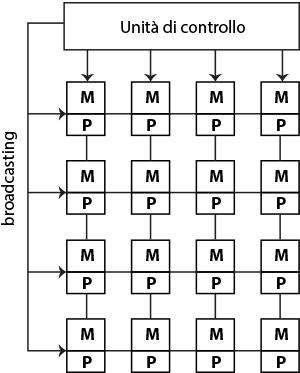
Fig. 5 - Processore vettoriale con griglia di 4x4 Processore (P) ognugno con la sua memoria (M)
Un processore vettoriale è composto da una unica unità di controllo che invia in broadcast la singola istruzione eseguita da una griglia di processori ognuna con la propria memoria.
La pipeline nel caso di processori vettoriali sarebbe la seguente:
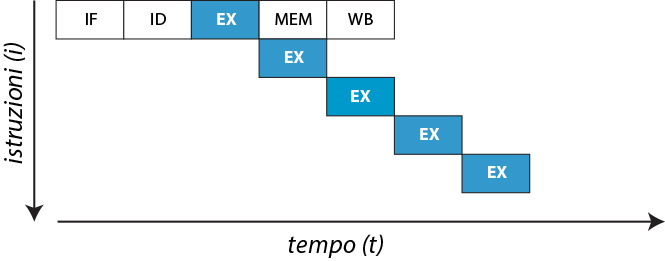
Fig. 6 - Pipeline processore vettoriale
Dopo la decodifica dei dati la pipeline continua a processare dati senza dover decodificare altre istruzioni.
Una unica operazione vettoriale opera su più dati contemporaneamente in questo modo si leggono meno dati rispetto ad un classico processore (vengono letti contemporaneamente).
Gli accessi alla memoria vengono ottimizzati in quanto i dati vengono salvati in ampi registri vettoriali.
Volendo mettere a confronto le architetture pipeline e processori scalari e le architetture array processor, nelle prime il tempo di calcolo dipenderà linearmente dal numero di elementi e non dalla profondità dell’algoritmo; nelle seconde, invece, il tempo di calcolo dipenderà dalla profondità dell’algoritmo e non dal numero di dati.
Vediamo con un esempio le differenze.
Immagininiamo di avere come problema da risolvere, la somma di due vettori.
Nel caso di un processore scalare, è necessario effettuare le somme ciclando su ogni cella dei due vettori per farne la somma e deporre il risultato nella corrispondente cella di un terzo vettore.
for(int I = 0;I < n; i++){
C[i] = A[i] + B[i];
}
in questo caso i tempi di esecuzione sono relative esclusivamente al numero di dati. Più grandi sono i vettori e più tempo impiega l’operazione.
Se invece volessimo risolvere tale problema in un processore vettoriale, non avremmo bisogno di un ciclo in quanto si può parallelizzare l’operazione somma su ognuna delle posizione delle celle.
C[1:n] = A[1:n] + B[1:n]
E’ evidente che in questo caso il tempo di esecuzione dipenderà dalla profondità dell’algoritmo e non dalla dimensione del dati. Proprio perchè se abbiamo a disposizione n processori sarà possibile sommare le coppie di celle dei due vettori in una sola istruzione.
Chiaramente non sempre si avrà a disposizione un numero n di processori e quindi non sarà possibile risolvere l’operazione con una sola istruzione, tuttavia si possono scomporre i vettori in tanti sotto vettori ed ottenere comunque un numero di istruzioni ancora ridotto da eseguire rispetto al caso di un processore scalare.
Multiprocessori
Un vettore di processori non è costituito da più unità di elaborazioni indipendenti visto che c’è una unità di controllo condivisa tra tutte le altre unità.
Un sistema parallelo composto da più processori è invece il multiprocessore. Cioè un sistema composto da più processori con una memoria in comune.
Le architetture multiprocessore sono asincrone per la presenza del controllo all’interno dei singoli nodi. Nonostante ciò è necessario comunque prevedere dei meccanismi di sincronizzazione (code, semafori..) per regolare l’accesso alle risorse condivise.
Ad esempio essendo la memoria condivisa, quando i processori interagiscono con essa devono coordinarsi. I microprocessori e la memoria in questo caso si dicono strettamente legate (tighly coupled).
Un esempio di multiprocessore tighly coupled è mostrato dalla seguente figura in cui si osservano quattro processori connessi ad un unico bus collegato alla memoria (UMA – Uniform Memory Access)
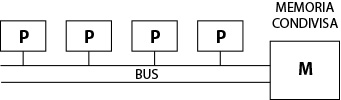
Fig. 7 - UMA (Uniform Memory Access)
Una variante di questo tipo di architettura è quello che prevede che ogni processore possegga una propria memoria locale accessibile solo al processore che la detiene (NUMA – Non-Uniform Memory Access).
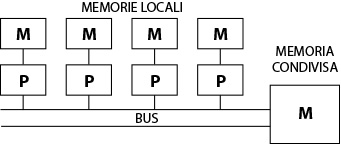
Fig. 7 - NUMA (Non Uniform Memory Access)
Nei sistemi multiprocessore il problema di interconnettere i vari processori è un problema rilevante.
Il problema della comunicazione tra unità è concentrata in un’unica unità switch.
Tuttavia essendo che gran parte dell’efficienza è legata a questa unità switch, la scelta di come connettere le unità è di centrale importanza.
A volte la struttura di interconnessione è composta da un semplice bus ma all’aumentare degli n processori chiaramente è facile trovarsi con un collo di bottiglia.
L’altra soluzione prevederebbe invece di creare un collegamento per ogni coppia di unità ma questo comporterebbe dei costi considerevoli essendo che bisognerebbe prevedere n x n bus di collegamento.
Per avere complessità minima senza rinunciare ad un elevato numero di nodi, si ricorre a schemi di interconnessione indiretta o dinamica come:
- bus multipli
- crossbar switch
- connessioni multistadi
Il sistema più semplice per sviluppare una unità di switch è quella di crossbar switch che prevede che ogni coppia di nodi sia collegata tramite uno switch elementare.
L’unità è una matrice a due dimensioni sulle righe i processori e sulle colonne le memorie. La complessità è pari a n2 pari al numero di switch elmentari da prevedere. In questo caso la complessità è pari a n2 e quindi i costi elevati.
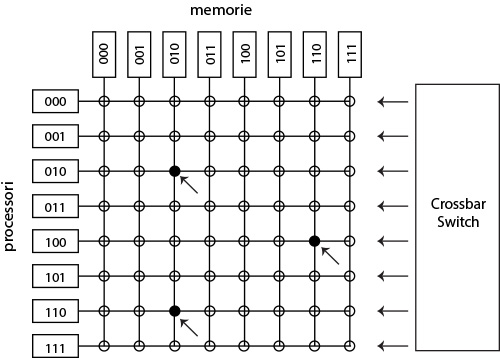
Fig. 8 - Crossbar switch
Una alternativa valida è quella delle connessioni multistadi.
L’idea è quella di prevedere un numero M di switch che a loro volta sono crossbar switch (con M < n). In questo modo si avranno M x M crossbar switch e la complessità passerebbe da n2 a logMn.
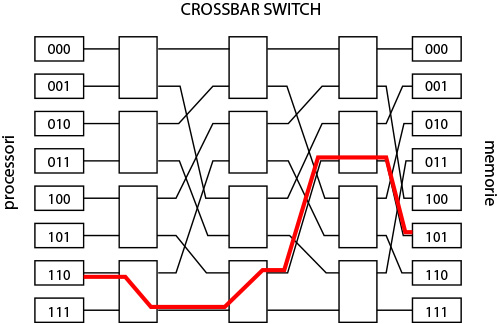
Fig. 9 - Connessioni multistati
Procollo MESI
Quando si parla di multiprocessori a memoria distribuita, uno dei problemi che deve essere gestito è quello della coerenza della cache e l’aggiornamento dei dati così che essi siano coerenti per tutto il sistema.
Vediamo un caso specifico in cui un dato potrebbe non essere coerente.
Immaginiamo esistano il processore CPU0 ed il processore CPU1.
CPU0 preleva il dato X dalla memoria attraverso una read e lo salva nella propria memoria attraverso una store. Dopodichè il processore CPU1 preleva dalla memoria centrale lo stesso dato X con una read e lo memorizza nella propria cache con una store.
CPU0, però, ad un certo punto modifica il suo dato X. Ma in questo modo il dato X che sta nella memoria cache di CPU1 non è più coerente e se CPU1 lo modifica e lo va a salvare nella memoria central e poi fa lo stesso anche CPU0, chiaramente uno dei due dati è perso senza che l’intero sistema se ne accorga.
Il protocollo che viene utilizzato è detto MESI (Modified, Exclusive, Shared, Invalid).
Ogni blocco di dati è accompagnato da uno stato che determina il livello di coerenza.
Quando un dato è modified (M), allora significa che il dato è presente solo nella cache di quell processore e che quindi non esistono copie in altre cache. Inoltre quel dato in memoria centrale non è aggiornato.
Un dato diventa Exclusive (E) quando la sua copia nella cache è unica e non modificata, non è presente nelle altre cache e in memoria quell dato è aggiornato.
Un dato diventa shared (S) quando la copia in cache non è stata modificata, è presente anche nelle altre cache ed è aggiornato in memoria.
Un dato diventa invalid (I) quando il dato in cache non è più utilizzabile.
Problema1: CPU1 usa un vecchio valore che era già stato modificato da CPU0.
Soluzione: invalidare tutte le copie prima di permettere che che avvena una write
- CPU0 legge X dalla memoria, memorizza X nella sua cache. Il dato X è di tipo E;
- CPU1 legge X dalla memoria, memorizza X nella sua cache. Il dato X in entrambe le cache diventa S;
- CPU0 modifica X e lo memorizza nella propria cache. Il dato X nella cache di CPU0 diventa M (Modified) mentre quella nella cache di CPU1 diventa I (Invalid);
- CPU0 effettua la memorizzazione del dato X nella memoria centrale;
- CPU1 legge X dalla memoria e la registra nella sua cache. Il dato X diventa Shared nelle due cache;
Da questi passi si evince che una cache può soddisfare una read solo se non è nello stato Invalid (I).
Una write invece può essere eseguita solo se il blocco in cui vi è il dato è M (Modified) oppure E (Exclusive). Se invece il dato è S (Shared) prima deve essere invalidato ovunque. Questa operazione è eseguita tramite una operazione di broadcast chiamata Read For Ownership (RFO).
I multicomputer
Mentre i multiprocessori sono costituiti da processori che hanno accesso alla stessa memoria (sistemi con spazio di indirizzo singolo o condiviso), i multicomputer sono costituiti da calcolatori con spazi di indirizzi separati o distribuiti.
I computer possono essere connessi tra di loro in maniera:
- diretta solo alcuni computer sono realmente connessi (generalmente i più vicini) ed indirettamente connessi agli altri;
- indiretta, ogni nodo è connesso a tutti tramite una rete di interconnessione;
Nel primo caso, la connessione è contraddistinta da una topologia di rete piuttosto che uno switching.
La decomposizione di un problema nel contesto dei multicomputer è ben più complessa rispetto ai multiprocessori in quanto non abbiamo risorse condivise e tra l’altro abbiamo notevoli ritardi nella comunicazione che in questi casi è di tipo Message Passing.
La comunicazione può essere sincrona o asincrona. Nel caso in cui la comunicazione è sincrona chiaramente i due computer devono prima sincronizzarsi per poter trasferirsi dati. Nel secondo caso invece si fa uso di buffer di dati così che il mittente può inviare dati quando vuole e il ricevente prelevarli da un buffer quando vuole.
Cosa abbiamo imparato da questa lezione
Conoscenze
- Cosa sono le tipologie di architettura CISC e RISC e quali sono le differenze
- Cos'è una Pipeline e quali i suoi benefici
- Cosa sono e quali sono le dipendenze in una pipeline
- Il concetto di parallelismo
- Cos'è una architettura parallela
- Quali sono le tipologie di architetture parallele
- Cosa è un processore superscalare
- Cosa è un processore vettoriale
- Cosa è una architettura multiprocessore
- Cosa è il protocollo MESI e come funziona
- Cosa sono i multicomputer
Abilità
- Siamo in grado di riconoscere in quali i vantaggi del parallelismo
- Siamo in grado di distinguere in una architettura multiprocessore collegamenti UMA e NUMA
Competenze
Nessuna particolare competenza
Fig. 3 - Processore superscalare primo approccio
Fig. 4 - Processore superscalare secondo approccio
Fig. 5 - Processore vettoriale con griglia di 4x4 Processore (P) ognugno con la sua memoria (M)
Fig. 6 - Pipeline processore vettoriale
Fig. 7 - UMA (Uniform Memory Access)
Fig. 7 - NUMA (Non Uniform Memory Access)
Fig. 8 - Crossbar switch
Fig. 9 - Connessioni multistati
| Conoscenze |
|
| Abilità |
|
| Competenze | Nessuna particolare competenza |
Sede legale e operativa
Via Dei Pini, 56
84040, Vallo Scalo (Staz.)
fraz. di Casal Velino, Salerno
Email: [email protected]
PEC: [email protected]